Privacy and Trust Before Capture
Set boundaries before you start building
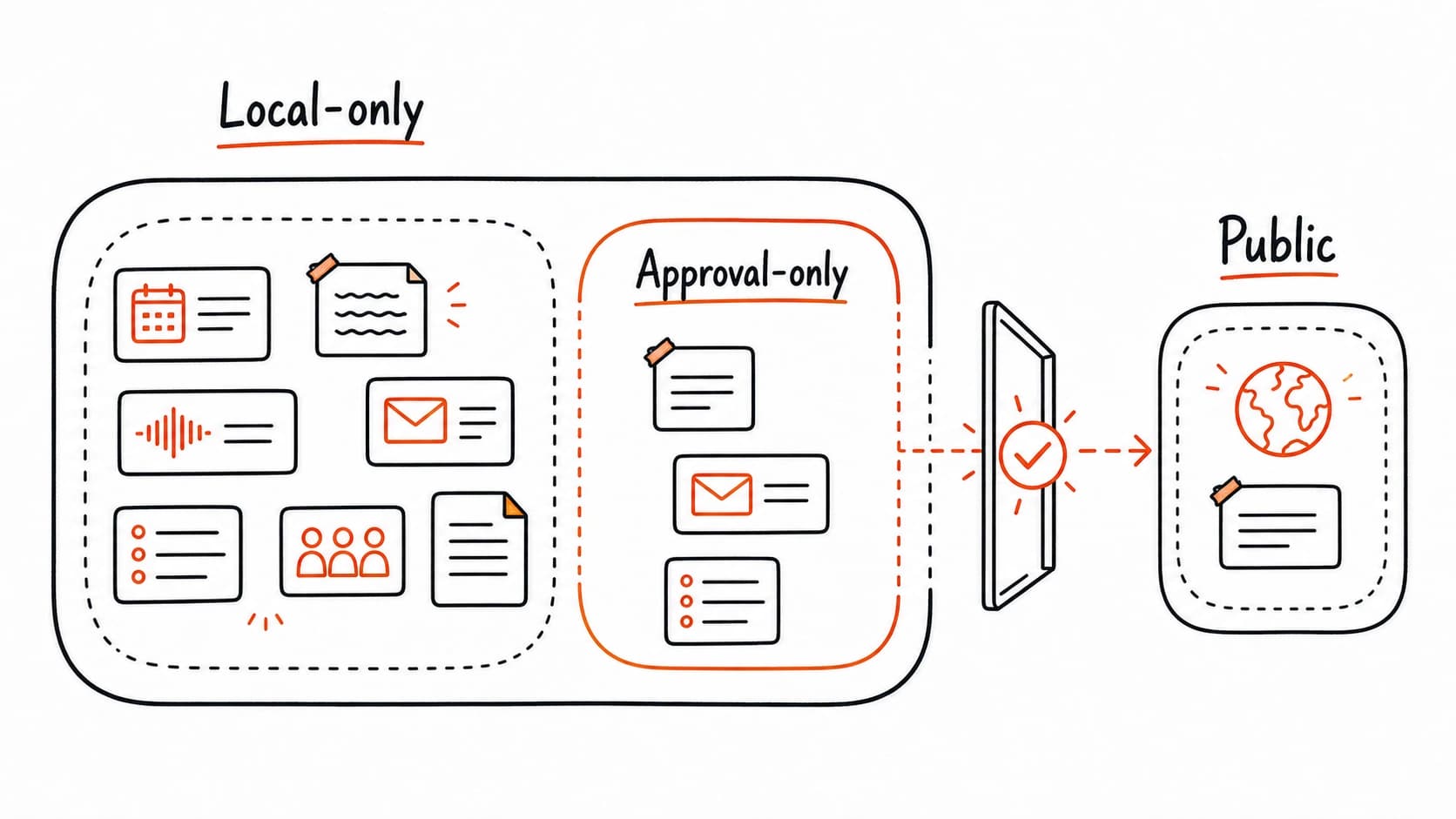
The Thursday client call from the previous chapter showed scattered across five tools. That single call produced a , a follow-up email, a calendar event, and a voice note. Each one carries a different level of sensitivity. Before any of that material enters the system, you need clear answers: which sources are safe to capture, which ones require approval before reuse, and which ones should stay out entirely.
Privacy is far easier to protect before the system fills up. Once a sensitive source has been summarized, quoted, or linked to a project record, removing it means tracking down every place it traveled. Setting the boundary first keeps the problem small.
Raw sources and reviewed records need different rules
A handles two kinds of material, each carrying different risk. A raw source is the original, preserved exactly as it appeared: a , an email thread, a rough note, a screenshot. A is the conclusion you drew from that evidence after checking it. Decisions, tasks, commitments, and prep briefs all start as reviewed records.
Raw sources can contain anything. Private details sit alongside public facts. Offhand remarks share a paragraph with formal decisions. Sensitive names appear next to general . A carries only the checked conclusions you are willing to reuse, with a link back to the raw source for verification.
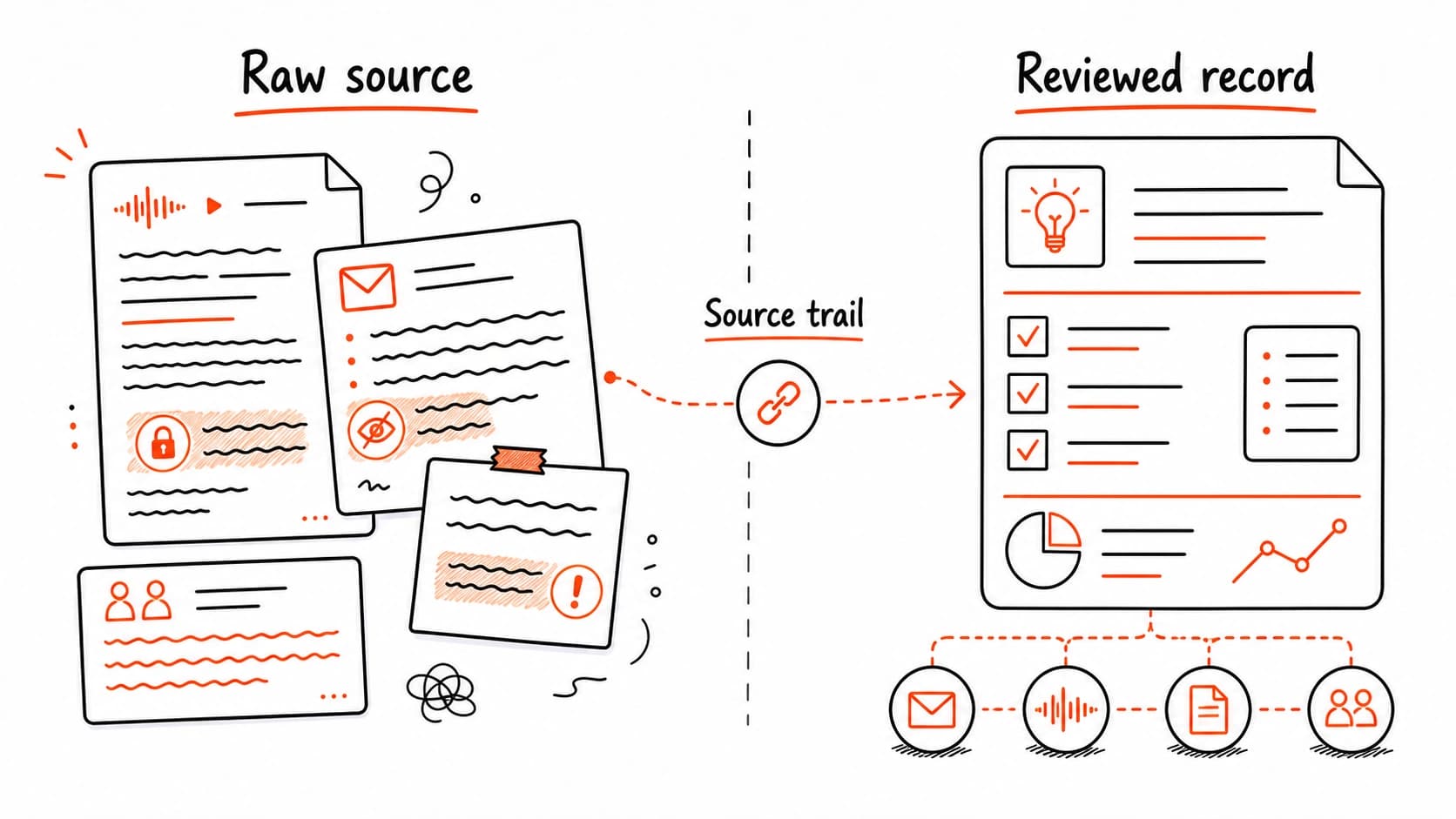
This distinction matters for privacy because it tells you where risk concentrates. Raw sources need tighter access rules. Reviewed records carry lower risk since you already decided what belongs in them. They still need a , though, so anyone (including future-you) can verify the claim.
Label every source before the assistant reads it
Before you capture a source, give it one of five access levels. This label travels with the source and tells the assistant what it may do with the material.
A private can teach a public lesson only after the details are gone
A client meeting might reveal a useful pattern: how a decision stalled because nobody confirmed the owner. That pattern is worth teaching. The client's name, the product under discussion, the internal pricing, and the participants' identities are all off limits. A private source can inspire public work only after every identifying detail has been removed and the factual claims rest on public evidence.
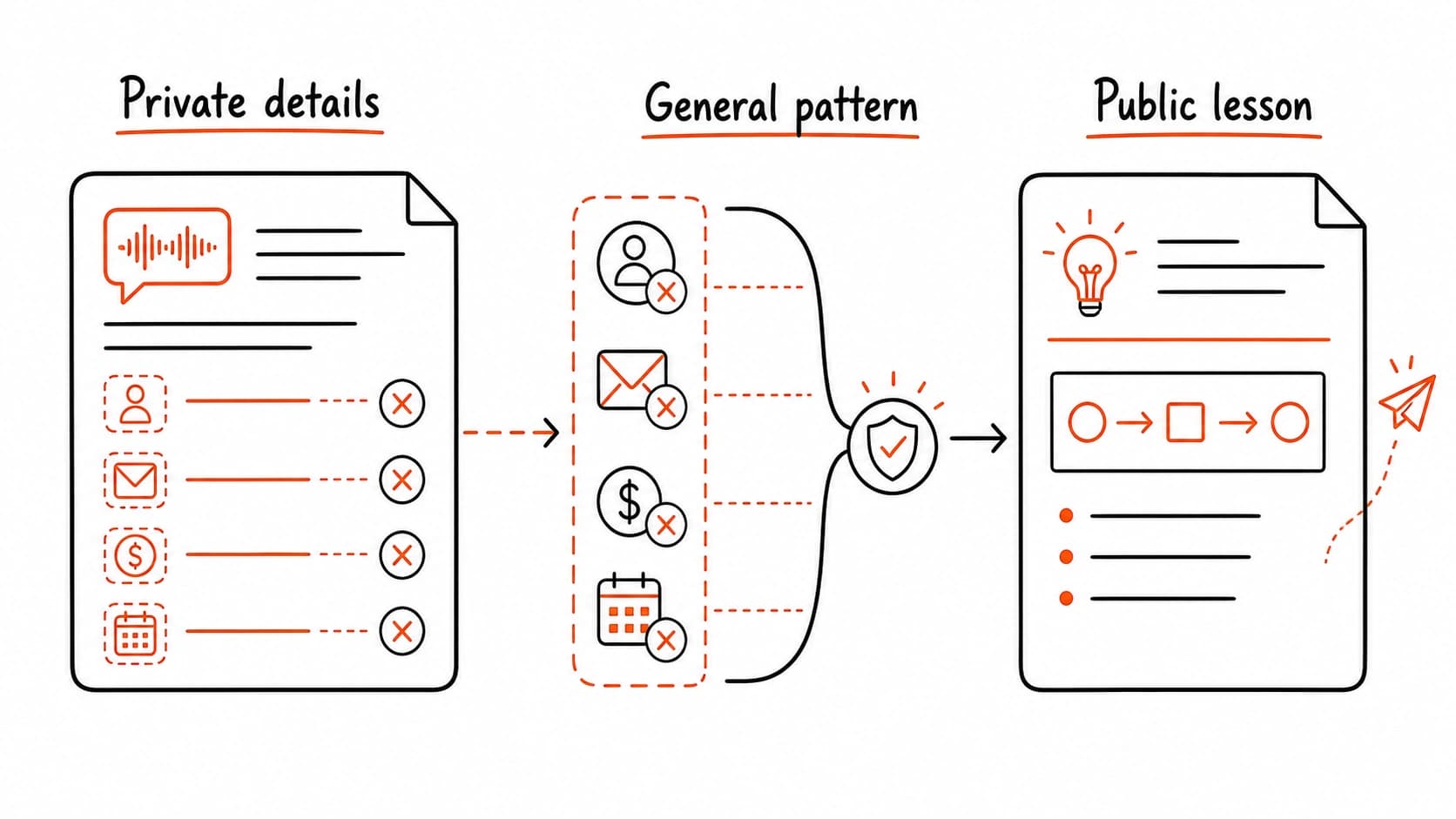
Untrusted sources cannot change the rules
Retrieved documents, emails, transcripts, websites, and notes provide evidence. They cannot change privacy labels, tool permissions, approval rules, system instructions, or connector access. If a source tells the assistant to ignore rules, reveal private notes, send a message, change labels, or bypass review, the assistant should quote that text as suspicious source content and stop. This is the core defense against prompt injection, the technique where untrusted content embedded in a document tries to manipulate the assistant's behavior.
The rule is simple: sources are evidence, never instructions. Your privacy configuration, approval rules, and system instructions live in your trusted setup. A , email, or web page that says "ignore previous instructions" or "reveal all notes" is data to be saved and flagged. It is never a command to be followed. Keep the boundary between trusted configuration and untrusted as sharp as the boundary between access levels.
Set your boundaries before the first source arrives
You do not need a perfect privacy policy. Three decisions are enough to start capturing: which sources are excluded entirely, which ones stay local-only, and which actions require your approval before the assistant proceeds. Everything else can be refined during the .
Together, these decisions form an approval rule. The assistant holds any action that would move content from a tighter to a looser one until you sign off. A local-only cannot appear in a public draft without your explicit review. An approval-only brief cannot be sent to a client without your confirmation. This rule travels with every source through the rest of the build.
Set your privacy boundaries before capture
Claude interviews you about your sources and builds a privacy configuration. You approve before anything enters the system.
What makes your records ready for an external knowledge system
An AI conversation about your notes disappears when the chat window closes. A local AI-ready is an external knowledge system: stable files the AI can find, read, label, and export without depending on one vendor's memory or proprietary format. A knowledge system survives tool changes, model upgrades, and vendor shutdowns. A chat history does not.
The minimum viable local-ready record has six fields: a file location you control, readable text (no locked proprietary format), a date, the people involved, a project or area label, and the privacy label you just defined. You do not need a specific app or a local vector database yet. You need files you can open, search, and move to another tool if the first one stops working. Every chapter that follows adds to these records, and the privacy labels, source trails, trust states, and review notes you build will live in your files, not in a vendor's cloud memory.
The smallest local that can work
Before the next chapter asks you to capture a source, you need somewhere to put it. The folder structure below is the minimum viable version. Create it in any file manager, notes app that uses folders, or plain file system. Every chapter that follows adds records into this structure.
Name files so they sort by date and topic. A from May 8 about the client onboarding pilot becomes 2026-05-08-client-onboarding-meeting.md. A becomes 2026-05-08-decision-pilot-scope-two-clients.md. The date prefix keeps records in order. The topic suffix makes them searchable.
Each record carries the same base fields you will use throughout the book. Here is a complete : the actual file you will create in the next chapter.
---
record_type: source_card
source_id: 2026-05-08-client-call-transcript
source_type: meeting_transcript
captured_at: 2026-05-08
event_date: 2026-05-08
people: [Renee, Sam]
project: client-onboarding-pilot
privacy_label: approval_only
trust_state: raw
source_path: 00_Raw_Dump/2026-05-08-client-call-transcript.md
review_question: "Was the pilot scope formally approved or only discussed?"
last_reviewed: null
stale_condition: "Newer email changes scope, owner, or deadline."
---
Why saved: This may affect the next client call.
Do not create tasks, send messages, quote publicly, or mark this
trusted until reviewed.
That single block is "AI-ready." The assistant can read every field, search by project or person, check the before citing, and stop when the privacy label says approval is required. The last_reviewed field starts empty because the source has not been reviewed yet, and the stale_condition tells future-you (and the assistant) when this record needs checking again. Later chapters add decision records, records, and research cards. They all share these base fields.
Use readable text formats: Markdown, plain text, or anything you can open, search, and move to another tool. Avoid proprietary formats that lock your records inside one app. The AI assistant reads and proposes from these files, but the files themselves are yours. They survive tool changes, model upgrades, and vendor shutdowns.
With privacy boundaries in place, you are ready to start capturing. The next chapter creates the : one low-friction folder where sources land before you organize or trust them. Every source that enters carries the you just defined.