Retrieval That Shows Its Sources
Every answer should point back to the record it came from
Your Thursday call now has a , a follow-up email, and a sort. Time for the real test: can you ask the system a question and get back the right source? is the act of asking a question and receiving an answer that shows where each claim came from. For your first try, use a record from the previous chapter. Ask what changed before Thursday's call, then check whether the answer links each claim to the right source.
The system earns trust through . If the answer cites the , the email thread, and the open question, you can verify each claim before acting. If the answer sounds plausible but cites nothing, you have a fluent guess instead of grounded knowledge.
Walkthrough: a that works
Ask: "What did we decide about the onboarding form, and who owns the next step?" The assistant searches your records and returns: the team approved a two-client pilot (source: from May 8, decision status: approved), Renee owns the draft agenda (source: follow-up email from May 9, status: tentative, pending confirmation). One open question remains: whether legal review finishes before the pilot starts (source: meeting record, status: unresolved).
Each claim has a . You can open the and verify the pilot decision has an approved decision status. You can open the email and check whether Renee's language was "I will send it" or "I'll try to send it." The source trail is what lets you act on the answer with confidence.
Walkthrough: a that fails
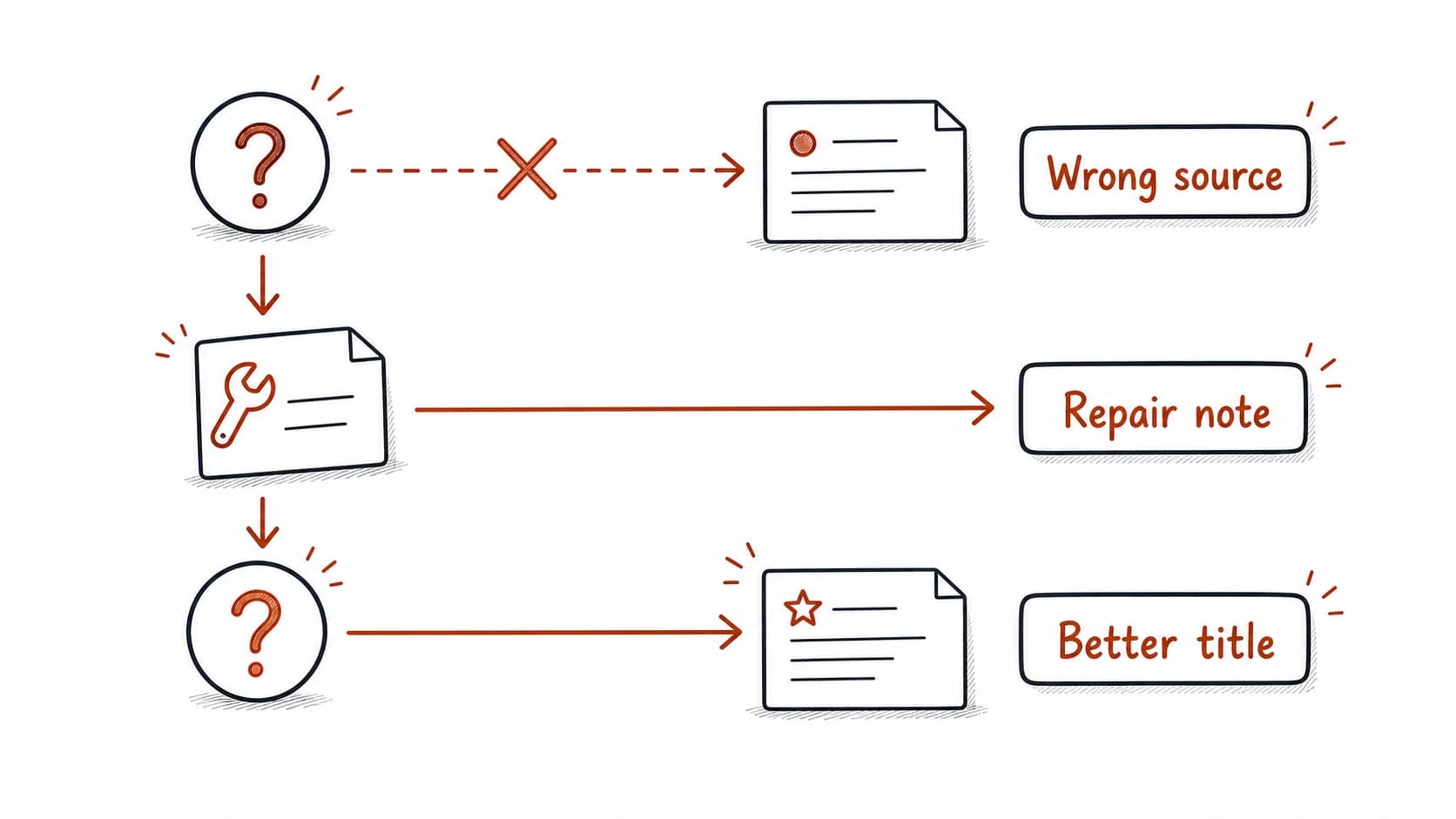
Now ask the same question, but this time the system returns the wrong source. Instead of the approved from May 8, the assistant finds an older planning note from April that says "consider onboarding form options." The planning note predates the decision by two weeks. If you trust the answer without checking the , you might reopen a decision that was already made.
A failed is useful when it leaves behind a repair. In this case, the approved may be missing a title that matches the question, or the planning note may have a stronger keyword match than the decision. The fix could be as simple as adding "onboarding form decision" to the approved record's title or creating an alias that points the question to the right source.
Failure path: stale
The most dangerous failure is one that returns an outdated answer that sounds current. The says "approved: two-client pilot." Three weeks later, the client expanded the pilot to four clients in an email you captured and organized, but never promoted to a . The still returns the original two-client decision because that record has a stronger . The current reality lives in a raw source that retrieval cannot see at the same confidence level.
The repair: during your , check whether any has been superseded by newer sources. A stale record should be updated or marked as outdated, with a link to the newer source that carries the current state.
When a and a newer unchecked source disagree
can return sources from different trust states. A reviewed and a raw planning note may both mention the onboarding form. The carries more authority because you approved it, but the raw source may contain newer information that has not yet been promoted.
When the assistant finds competing sources at different trust levels, it should show both with their and date, so you can decide which one governs. The answer should cite the as the current approved state and flag the raw source as potentially newer material that needs review before it can update the record.

at scale changes what you search for
With 20 sources, you can scroll through everything. With 200, you rely on search. With 2,000, you rely on the quality of your titles, tags, project labels, and source trails. As the system grows, quality depends less on what you captured and more on how well you organized and reviewed it. Titles that name the decision rather than the meeting date, project labels that match how you ask questions, and regular review that retires stale records all improve retrieval over time.
Add layers only when the current one stops finding the right source
Start simple and add layers only when the current one becomes the bottleneck. Most readers will stay on the first or second level for months. You do not need a vector database to start. Plain text files with good titles and carry most systems through the first several months.
Add when keyword search becomes the bottleneck. Add hybrid when single-method search misses records you know exist. Add retrieval tests when the stakes are high enough that a wrong answer would cost real time or trust. Each level builds on the previous one; skipping ahead without good titles and will produce worse results, not better ones.
Test retrieval with one real question
Ask your second brain a question. Claude searches your records and shows whether the right source came back.
Build a retrieval evaluation set
Claude generates test questions from your records and runs them to see what breaks.
The project is done when one answer survives inspection. You should be able to ask a question, open the cited source, see uncertainty, and save a repair when the answer points to the wrong place.