Turn Any Module Into Audio
Any text you trust can become audio you listen to while walking
Every in this book produces text: a morning brief, an email , a , a set of reading highlights. You can turn any of them into audio by adding one instruction to the end: also generate an audio version.
Voice is an output format. It works the same way as save as PDF or send this to my email. You add a to modules that already produce text you trust.
- A morning brief becomes a three-minute podcast you play while making coffee.
- A becomes a reflection you listen to on a walk.
- An email becomes a hands-free summary you hear in the car.
- Reading highlights become an audio notebook you revisit on a commute.
One service is all you need
You need one service. Two are worth knowing about: ElevenLabs and the OpenAI text-to-speech API. Both accept text in and return audio out. Both let you choose a voice. Both cost a few dollars a month at personal-use volume. ChatGPT Plus subscribers already have built-in voice at no extra charge.
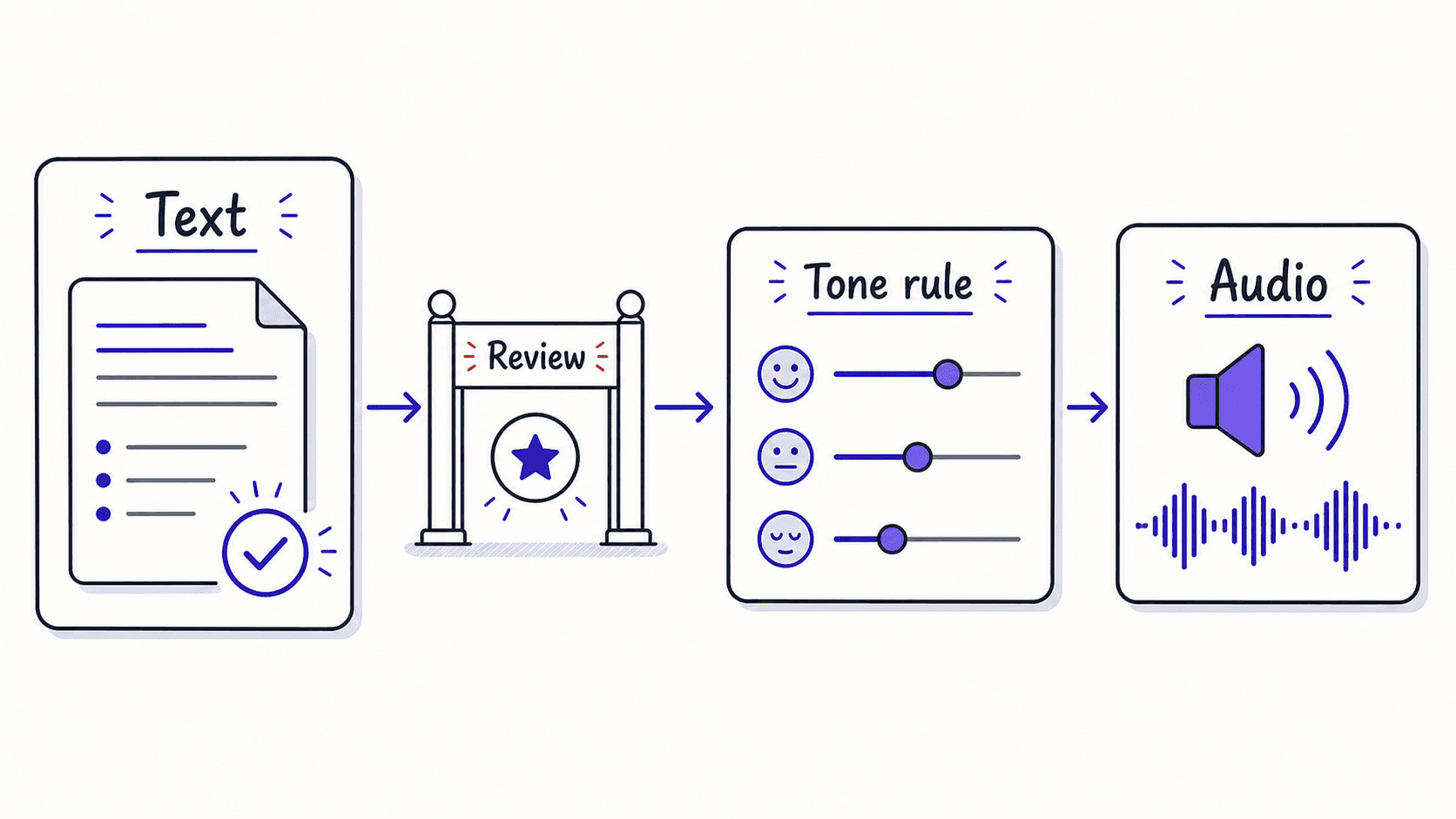
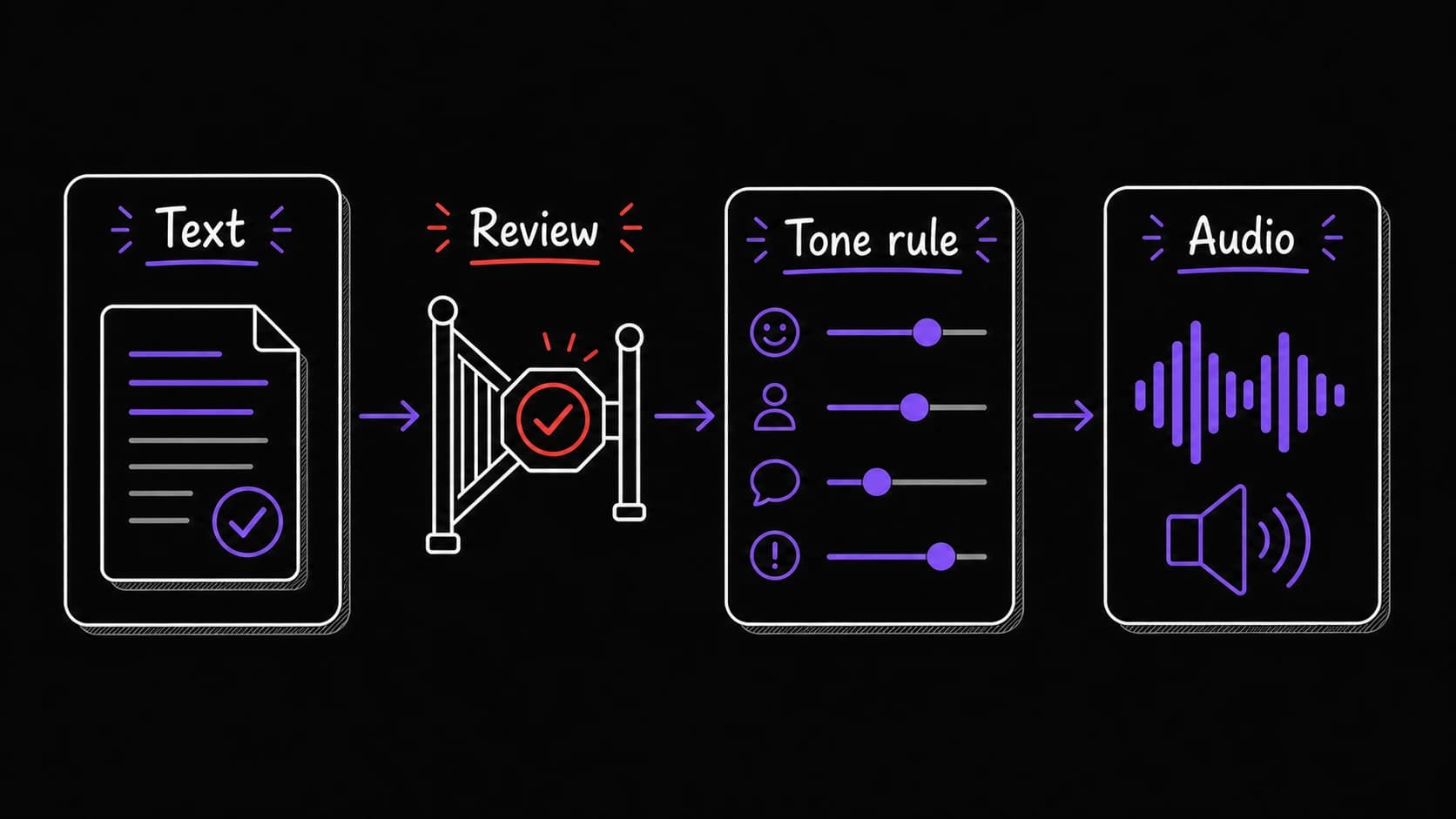
In practice, you tell the assistant 'convert my morning brief to audio using a calm tone' and review the file it creates. The prompt structure is identical for either service: describe the text to convert, which voice to use, and what tone to apply. You can switch services later without rewriting your prompts.
Tone instructions change the same words into different listening experiences
Modern services accept natural-language instructions for how to read the text. The words stay identical; the delivery changes.
Include the tone as part of your 's output specification, the same way you would specify keep it under 300 words or use bullet points for action items.
- A morning brief might get: read in a calm, professional tone at a moderate pace.
- A might get: read in a reflective, unhurried tone with natural pauses between sections.
- A set of reading highlights might get: read in an engaging, curious tone, as if sharing interesting findings with a friend.
The morning podcast is your first voice build
You already built your morning brief in the previous chapter. Now you add audio output. When you open your phone and press play, a three-minute audio file tells you what is on your calendar, who you are meeting, and what needs a reply.
The brief plays while you make coffee. By the time you sit down, you already know your day.
A read-anything makes voice reusable across every
The morning podcast is one use. Save a reusable called something like 'read this to me.' The skill accepts any text input, applies your preferred voice and tone, and returns audio. You can invoke it from any conversation: run my read-this-to-me skill on today's journal entry, on the , on an article you just highlighted.
Every you build in this book can pass its output through this one . You build voice once and reuse it everywhere.
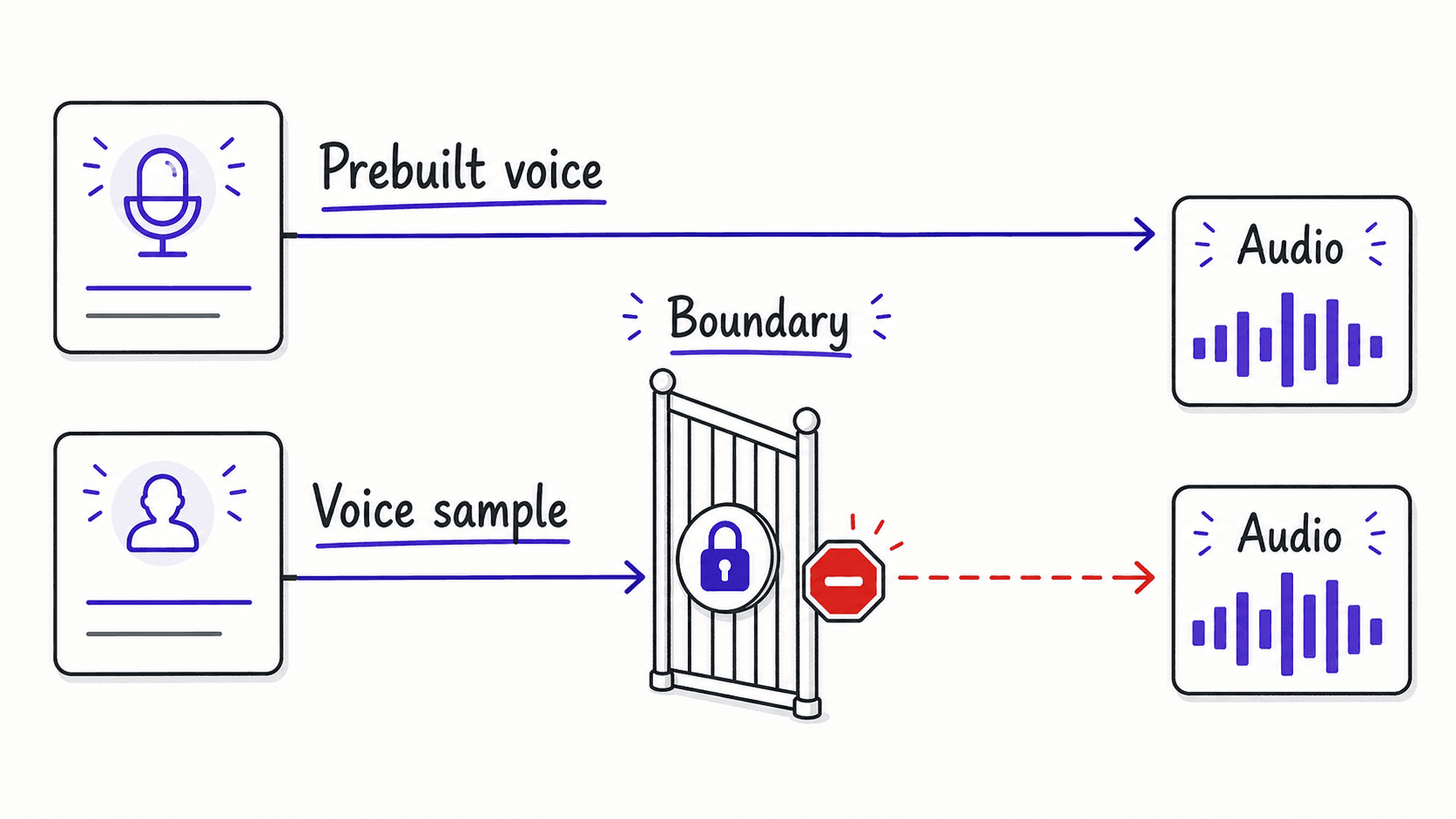
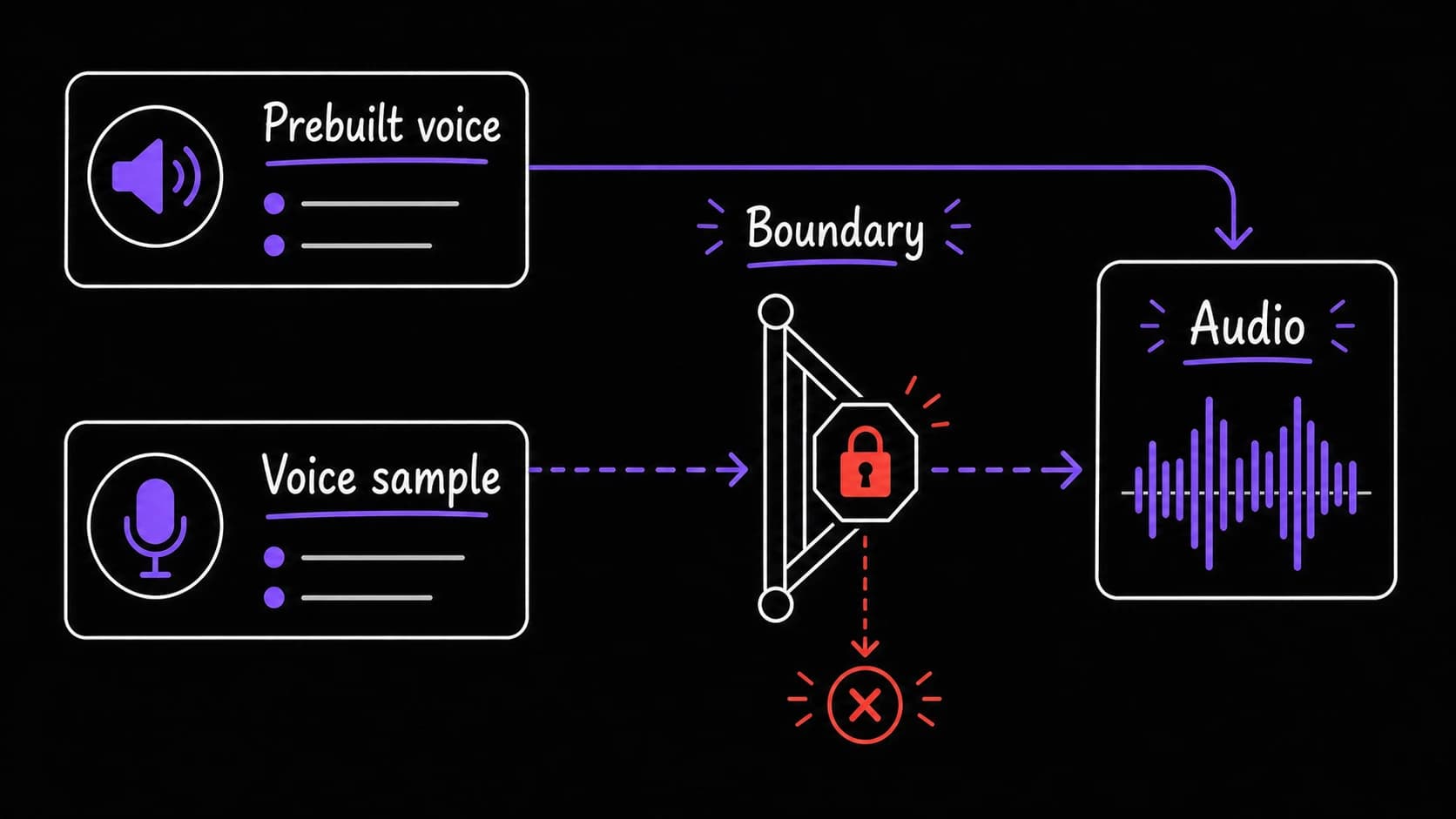
Voice cloning is the one privacy decision unique to this layer
Voice data raises fewer privacy questions than email or calendar data because the input is text you already reviewed. If the morning brief text was safe to process through the assistant, the audio file created from that same brief is equally safe.
The one consideration unique to voice: if you use voice cloning (available through ElevenLabs), the cloned voice sample lives on their servers. Some readers will prefer a pre-built voice to avoid uploading a sample of their own voice. The book's standard applies here as everywhere: decide the privacy boundary before you build, and tell the assistant what it is.