They brief AI like a collaborator because search-engine defaults quietly hold the work back
Chapter Progress: Early DraftA wealth of information creates a poverty of attention.
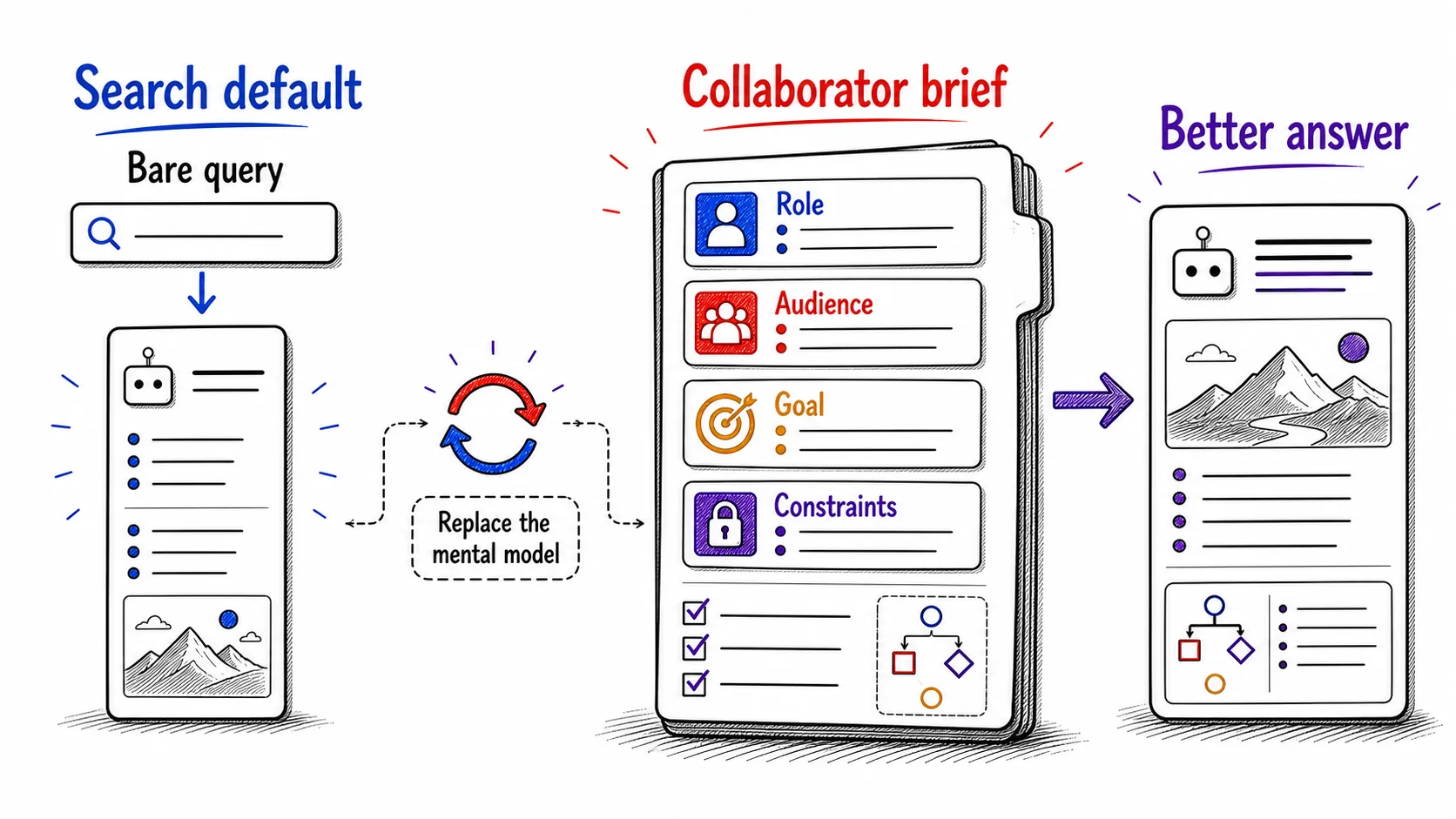
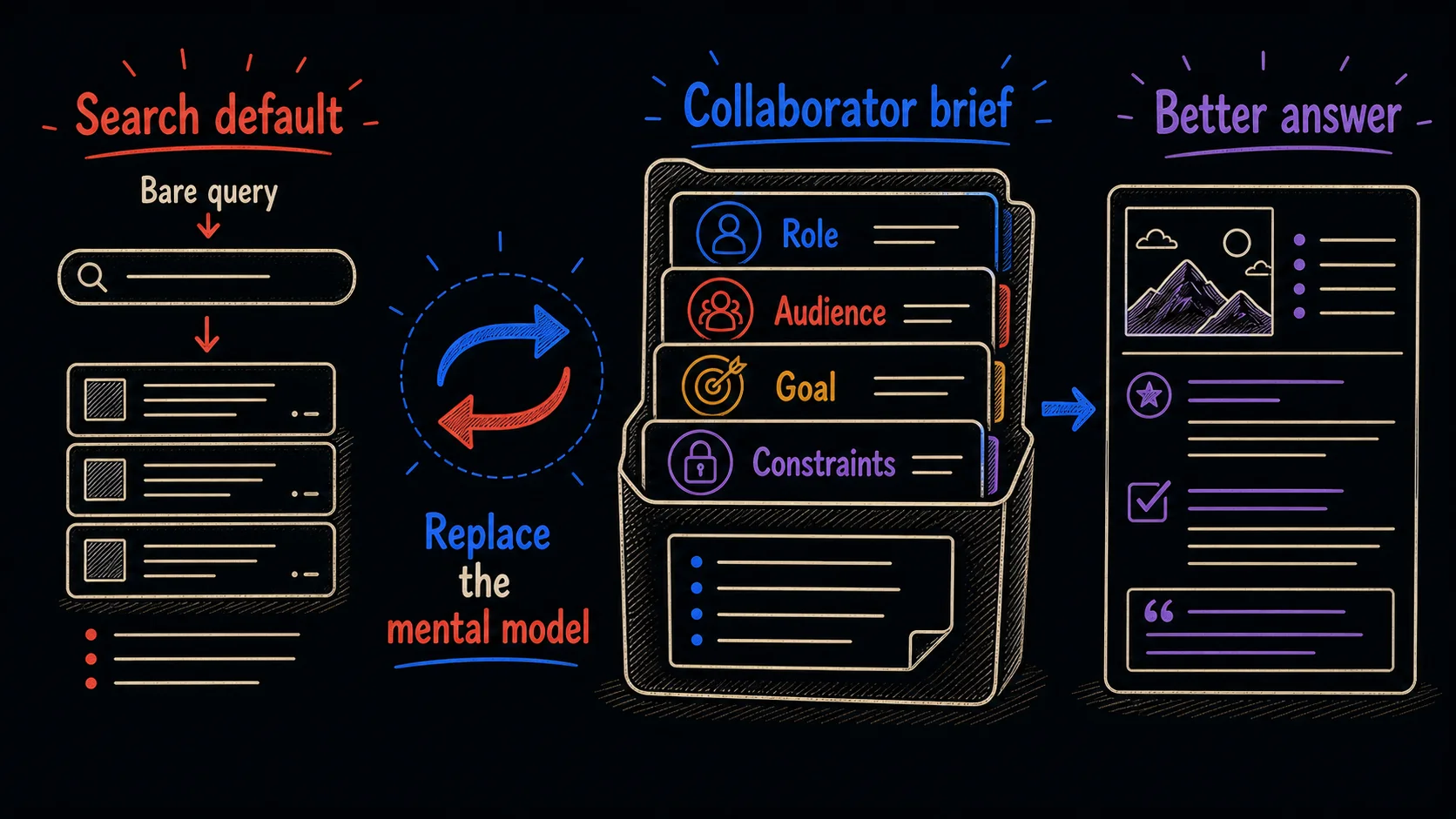
One old habit interfering with a new tool tends to underlie all five defaults
Start with why these habits are sticky, because the reason is the same for all five and it changes how you fix them. Each default is a skill you learned somewhere else, where it worked, and carried into AI, where it does not. A habit that served you well in its old home is the hardest one to drop, because it never announces itself as a habit. It just feels like the obvious thing to do.
Picture a tennis player picking up badminton for the first time. The tennis swing is grooved in after years of practice, so the player swings hard at the lighter shuttle and sends it sailing past the line. The old skill is not weak. It is too strong for the new game, and its strength is exactly what makes it hard to soften. Your search-engine habits are the tennis swing, and AI is the badminton court.
The prose above has built the felt idea: an old skill, well practiced, now getting in the way. Here is the name researchers give it.
These five patterns surface across several credible sources on how people use AI, from Microsoft's 31,000-person survey to Anthropic's conversation data to practitioner reports from Ethan Mollick, Dan Shipper, and Lenny Rachitsky. The move that turns an invisible habit into one you can change is naming the inherited default, and one reliable way to do that is to hand an AI tool your recent chats and ask it to review them for these patterns, since a meta-prompt can spot the habit you would miss in self-recall.
Treating AI like a search engine produces search-engine-quality answers
The first default is the one the chapter is named for. A search engine answers questions that already have an answer somewhere: you type a query, scan the results, and find the page. An AI tool does something different. It generates new text from what you give it. When you prompt it the way you query a search box, you get the shallow end of what it can do, the rough equivalent of reading the first result without clicking through.
Watch the contrast on one task. Don't, on the search-engine default: you type 'tips for a performance review' and take the generic list that comes back, the same list anyone would get. Do, on the collaborator brief: you tell it you are writing a review for a teammate who is strong technically and quiet in meetings, that the goal is to encourage them to speak up without denting their confidence, and that you want two concrete examples of phrasing. The first prompt asks it to find something. The second asks it to build something only it could build for you, because only you supplied the situation.
The question that sorts the two: am I looking for something that already exists, or making something new? If you are finding a fact, a search engine is still the better tool, and that stays true as interfaces change. If you are generating, analyzing, comparing, restructuring, or synthesizing, you are in AI's lane, and a query-sized prompt leaves most of its ability on the table.
Quitting after one weak answer wastes the model's best work
The second default treats the first response as a verdict. The previous chapter, on turning every interaction into a compounding improvement, made the case that a first answer is better read as a measurement than as a final grade. This default is what happens when you skip that reading: a thin first answer arrives, you conclude AI cannot do the task, and you stop. Most often a weak first answer is not evidence that the task is beyond AI. It is evidence that the task needed more context or another pass.
Microsoft's usage data puts a number on the gap. Power users are 30 percent more likely than casual users to keep going when a first response is poor. Read that statistic from the other side and it describes the default: non-power users are the ones less likely to keep trying after an imperfect first response, so a thin answer becomes a stopping point right before the point where the work usually gets good.
Watch the contrast. Don't, on the one-and-done default: the draft comes back flat, you sigh, and you either fix it all by hand or give up on asking. Do, on the iterate-instead default: before quitting, you ask two questions. Did I give it enough context to know what good looks like here? Did I push back and ask for a specific change, not just a vague 'make it better'? If either answer is no, you have a next move rather than a dead end. and context-loading are learnable habits that the chapters on following up until the output matches and on choosing your input medium develop in full.
One giant prompt overwhelms the model's attention on every step
The third default crams the whole job into one breath. A prompt that asks the model to research, analyze, compare, format, and recommend in a single pass splits its attention across all of those at once. When one prompt carries five jobs, the output tends to come back shallow on all five, because no single step got full attention.
The same problem wears a second disguise, and it helps to recognize both. Instead of one giant prompt, you build one giant conversation: you keep piling research, drafts, corrections, examples, strategy, and formatting notes into a single thread until neither you nor the model can tell which job the conversation is supposed to do. The chapters on thinking through problems with AI and on choosing a collaboration mode develop the habit of giving each conversation one focused job and splitting complex work across separate, focused threads.
Watch the contrast. Don't, on the overload default: 'Research this market, compare the top three options against cost and speed, format it as a brief, and recommend one.' Do, on the staged default: first, 'Summarize the three key options from this document.' Then, 'Compare those three against cost and speed.' Then, 'Recommend the strongest one and explain why.' Each stage takes the previous output as its input, and the total quality is higher than the all-at-once version, because every step had the model's full attention.
Closing the tab without saving throws your best work away
The fourth default is the quiet one, because nothing breaks when you do it. You finish a session that finally produced something useful, you close the tab, and the prompt that worked, the context you built, the corrections you made, all of it goes with the tab. The next time a similar task comes up, you rebuild from zero, which means this default is the one that most directly stops your work from compounding.
Watch the contrast. Don't, on the no-save default: the session goes well, you grab the output you needed, and you close the window, so next month the same task starts from a blank box again. Do, on the save-what-worked default: after any session that produced something useful, you keep the working prompt somewhere you can find it again, labeled with the task type. You do not have to do the saving by hand. You can ask the AI to distill the session into a reusable prompt or a small standard and name it for you, so the collection grows on its own. Next month, you open the saved prompt instead of rebuilding from a blank box, and the chapter on saving reusable AI assets builds this into a full practice.
Assuming AI cannot do something locks in a stale test
The fifth default freezes a single old result into a permanent belief. The pattern is familiar: you try a task once, it fails, and you file away 'AI cannot do X,' often from a test that is months old. The trouble is that AI's abilities keep moving with each model update. A task that failed in early 2025 may run reliably on a current model in mid-2026, and a task that worked on one model may fail on another. A stale belief about what AI cannot do is expensive in a particular way: it stops you before you even try, so the belief never gets corrected.
Watch the contrast. Don't, on the capability-blindness default: you decided last year that AI was hopeless at a task, so you never point it there again, and you may never find out it can now do it well. Do, on the evolve-the- system default: you keep a short list of tasks you wrote off, turn that list into a standing stress-test, and have the system re-run it whenever a new model launches rather than trusting yourself to remember. The real jump is not the re-test itself but what you do with the result: when a task that used to fail now passes, you encode it into a reusable prompt, standard, or workflow, so the new capability becomes part of how you work rather than a one-time discovery. The chapter on stress-testing the frontier turns this into a repeatable protocol.
Fixing two of the five lifts quality before you touch the rest
You do not need to fix all five at once, and trying to would stall you. Across the practitioner reports, two of these defaults stand out for how much they give back when you correct them: treating AI like a search engine and quitting after one answer. Move the first by switching query-shaped tasks to generation and analysis tasks. Move the second by learning to iterate instead of accepting the first draft. Change only these two and leave the rest for later, and the quality of what you get back rises noticeably.
A fair question sits under all of this: if these habits are obvious once named, why do they survive being named? Researchers John Carroll and Mary Beth Rosson found the reason and called it the . The prose above has built the felt version of it, so here is the term.
The paradox loosens from both sides. The exercises here are short enough to try inside a normal workday, so the learning cost stays small. And making the running cost of the old habits visible, as this chapter does, tends to make the twenty-minute investment look cheap by comparison. Better still, you can hand most of the learning cost to the AI itself: ask it to draft the reusable prompt or standard, so the twenty minutes shrinks to a review.
One habit runs under several of these defaults: matching how you work to what each tool does well. Search engines are still the better tool for facts you can look up. Calculators are still better for a computation you already know how to set up. AI collaboration rewards a different set of moves: loading context, iterating, synthesizing, imagining what you could ask for that you have not tried yet, and encoding the prompts, standards, and workflows that worked. This way of working outlasts each interface, because it is about reading the task before you reach for a tool, and reading the task stays useful whether you type, speak, or one day think the request through a brain-computer interface. One way to live it: read what the task needs, choose the mode it calls for, and then encode the version that works into a prompt, standard, or workflow you can reuse and keep evolving.