They match the model to the task: powerful for reasoning, fast for routine, never the default for everything
Chapter Progress: Early DraftRead the task first, because the default model is tuned for speed
Every major AI tool, as of 2026, hands you more than one model, and the lineup follows a steady pattern across tools. There is a fast model built for speed and low cost, a balanced model for everyday work, and a powerful model for hard reasoning and high-stakes tasks. The names will keep changing. The three rough tiers keep showing up, because they answer three different needs.
The model selected for you is usually tuned for speed, not for the hardest work you might hand it. That default is a reasonable starting point for quick, well-defined tasks. It is a poor fit when the task carries real reasoning, careful analysis, or high stakes, because there the stronger model can often produce a clearly better result. Sending the strategy recommendation to a fast default and accepting whatever it returns is how a thin, generic answer slips through. The do-it-well version is to notice that this task earns the stronger model before you spend an hour on the weaker one's output.
The prose above has built the move: read what the task needs, then pick the lightest model that clears your bar. Here is the name for it.
Choosing the stronger model for higher-value work shows up in the data across many users. Anthropic's index finds that people working on higher-value, reasoning-heavy work reach for the strongest model far more often than people doing lighter tasks. The research also finds that higher-tenure users succeed at a higher rate, measured separately from the model they pick. The routing this chapter teaches you to do on purpose, sending harder work to the stronger model, tends to be the same move the data picks up at scale.
Route by what the task needs so the skill survives every model update
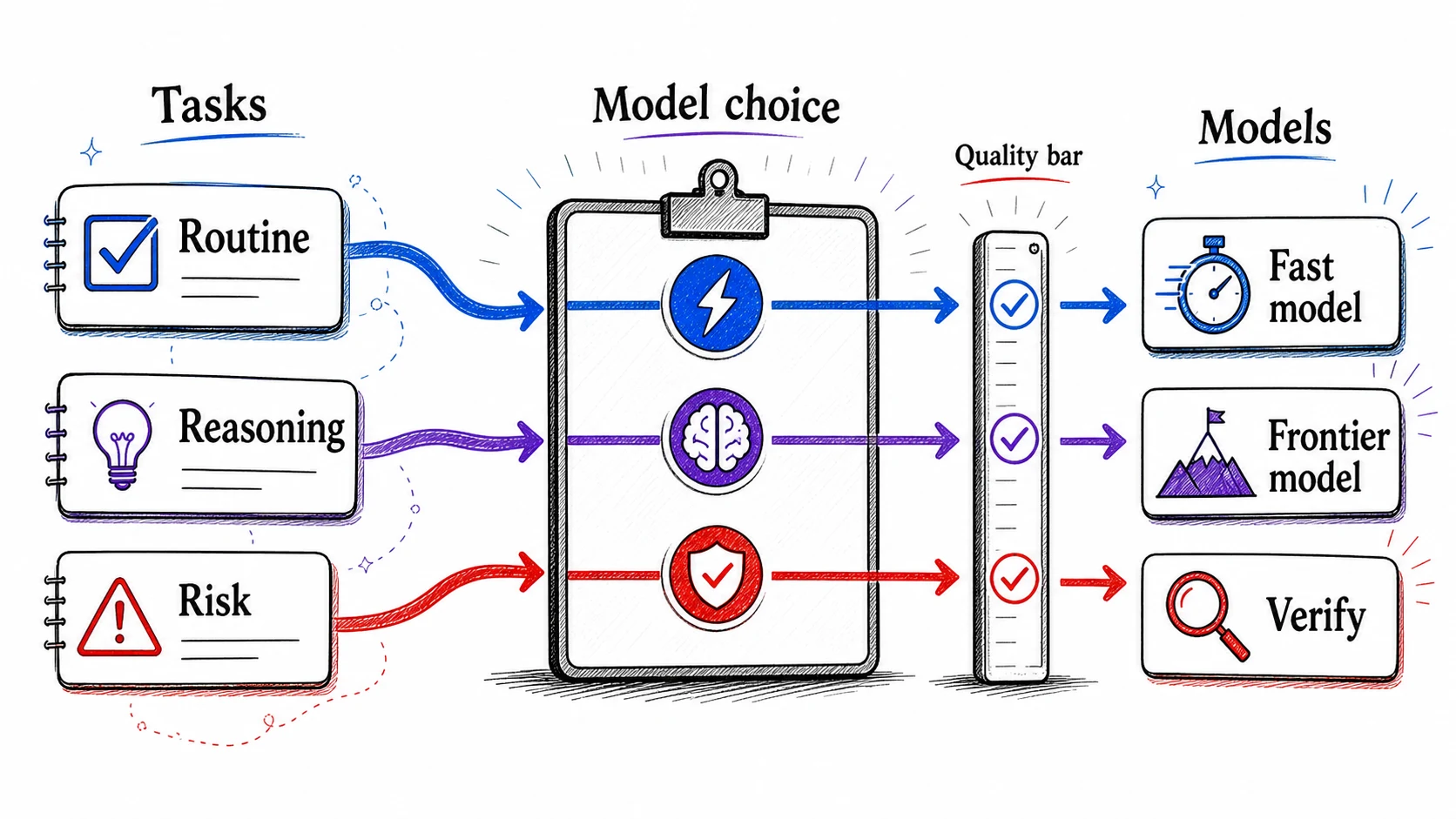
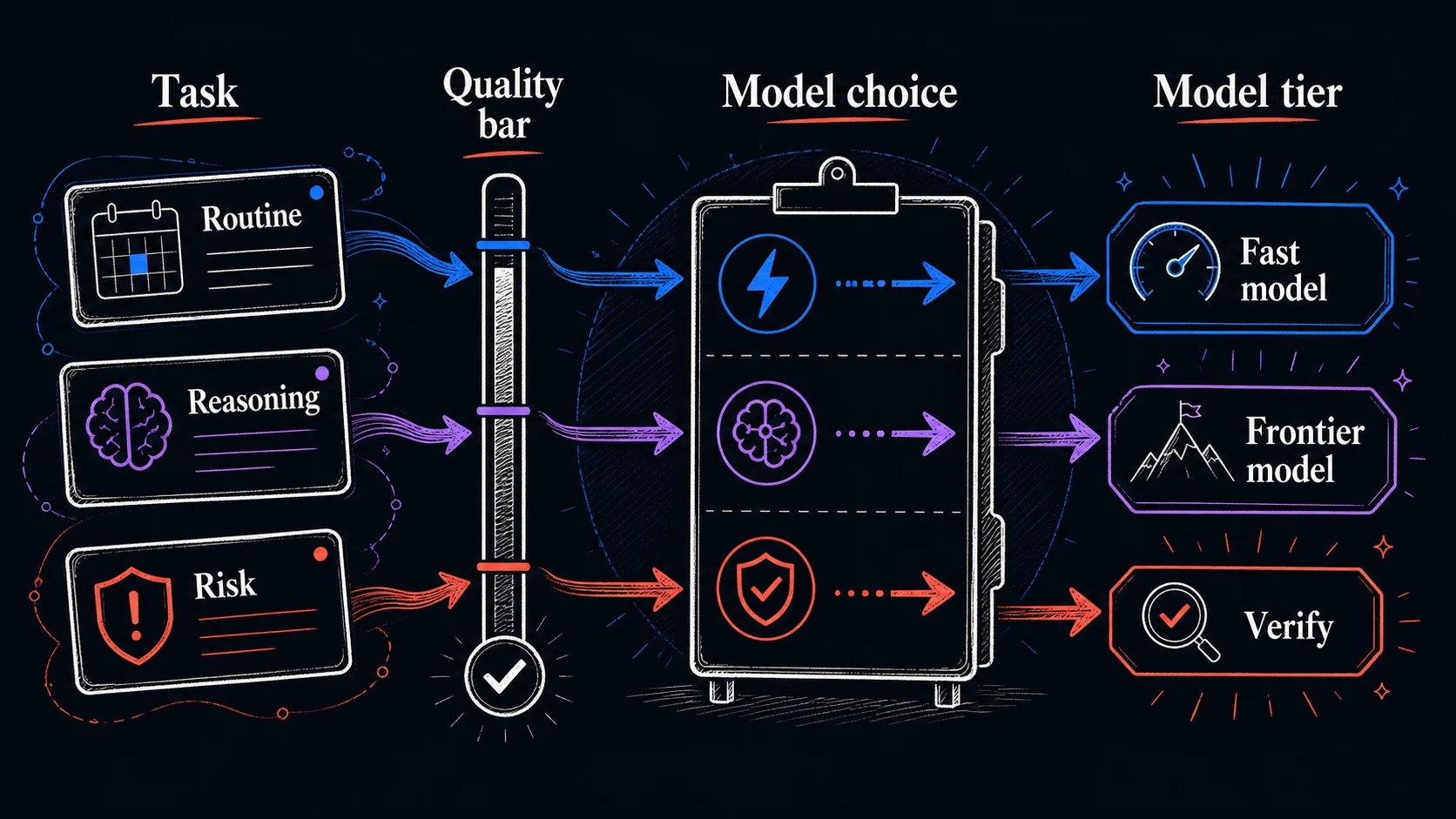
Model names change faster than the kinds of work you do. A skill that survives every update is reading the task type and choosing the lightest model that handles it reliably. To make that fast in the moment, it helps to sort tasks into a few named families, each with a model that tends to fit. Hold the families, not a list of one-off rules.
Five families cover most of what you will hand to AI: quick transformations, everyday professional work, high-stakes reasoning, current factual research, and file-and-action work. The table names each family, the kind of model it tends to want, and why. Read it as five buckets to drop a task into, not twenty rules to memorize.
One rule of thumb collapses the table when you are in a hurry: if the task needs judgment, reasoning about tradeoffs, or verifiable accuracy, reach for the powerful model. If it is routine, well-defined, and low-stakes, reach for the fast one. When you cannot tell, start strong and step down: run it on the powerful model first, then move it to the fast model once you have confirmed the fast one clears your bar on that kind of task. Starting strong and stepping down protects the work while you learn where the line is.
Test model differences on your own work, because reputations age fast
Beyond the tiers inside one tool, different model families have different tendencies, and people pass around quick claims about them: that one tool is more thorough, another more conversational, another stronger at search. Those claims may carry a grain of truth at the moment someone says them, and they age quickly. Every update shifts the balance, so a tendency you heard about last quarter may not hold today.
Treat any claim about a model's strengths as a hypothesis to test on your own task. Run the same task across two models, and you can have the AI score both outputs against a rubric you give it, so the evaluation is a check you set up rather than a judgment you eyeball alone. The same comparison is worth doing in a more playful register too: hand a fresh model a task you assumed it could not do, chase a 'wouldn't it be cool if it could' and see what it surprises you with, because the stronger tier sometimes opens a move you did not know to ask for. Your own task is the standard that counts, because it measures each model against the bar you actually care about. A ten-minute comparison, running one prompt through two models and recording which won and why, often teaches you more than a benchmark table, because it is scored on your work instead of someone else's.
Once a comparison settles a recurring task, write the result into a routing reference so the next session starts from a tested default instead of a fresh guess. This applies the move from the chapter on turning every interaction into a compounding improvement: the test you ran once becomes a reference your next self, or your AI, can read and act on. The reference is not frozen. When a model update shifts the balance, you can hand the reference back to the AI and ask it to re-run the comparison and propose the edit, so the reference evolves on its own and the re-checking stops being your job. Run enough comparison to keep the reference trustworthy, and let the system carry the upkeep once it can.
Build a routing reference from one tested comparison
Turn the comparison into a reference you keep, so the routing skill becomes a habit instead of a one-time test. Run your strategy recommendation, or whatever reasoning-heavy task you do often, on your everyday model and on your strongest model. Compare the two outputs on a few dimensions you care about, then write the result into a short reference table covering the five families. The prompt below has the AI help you design the test and build the reference. You run the test and keep the result.
References
1 source- 1Economic Index: Learning Curves.
Anthropic · 2026
Paid Claude.ai users send 55% of Computer and Mathematical tasks to Opus versus 45% of educational tasks. Users working on higher-value tasks (as measured by the typical wage for that type of work) are significantly more likely to choose Opus. The report separately finds that higher-tenure users show higher success rates.
Choosing the stronger model for higher-value work is an empirically documented power-user behavior, and experience tracks with success.