They follow up until the output matches because the first response is a measurement
Chapter Progress: Early Draft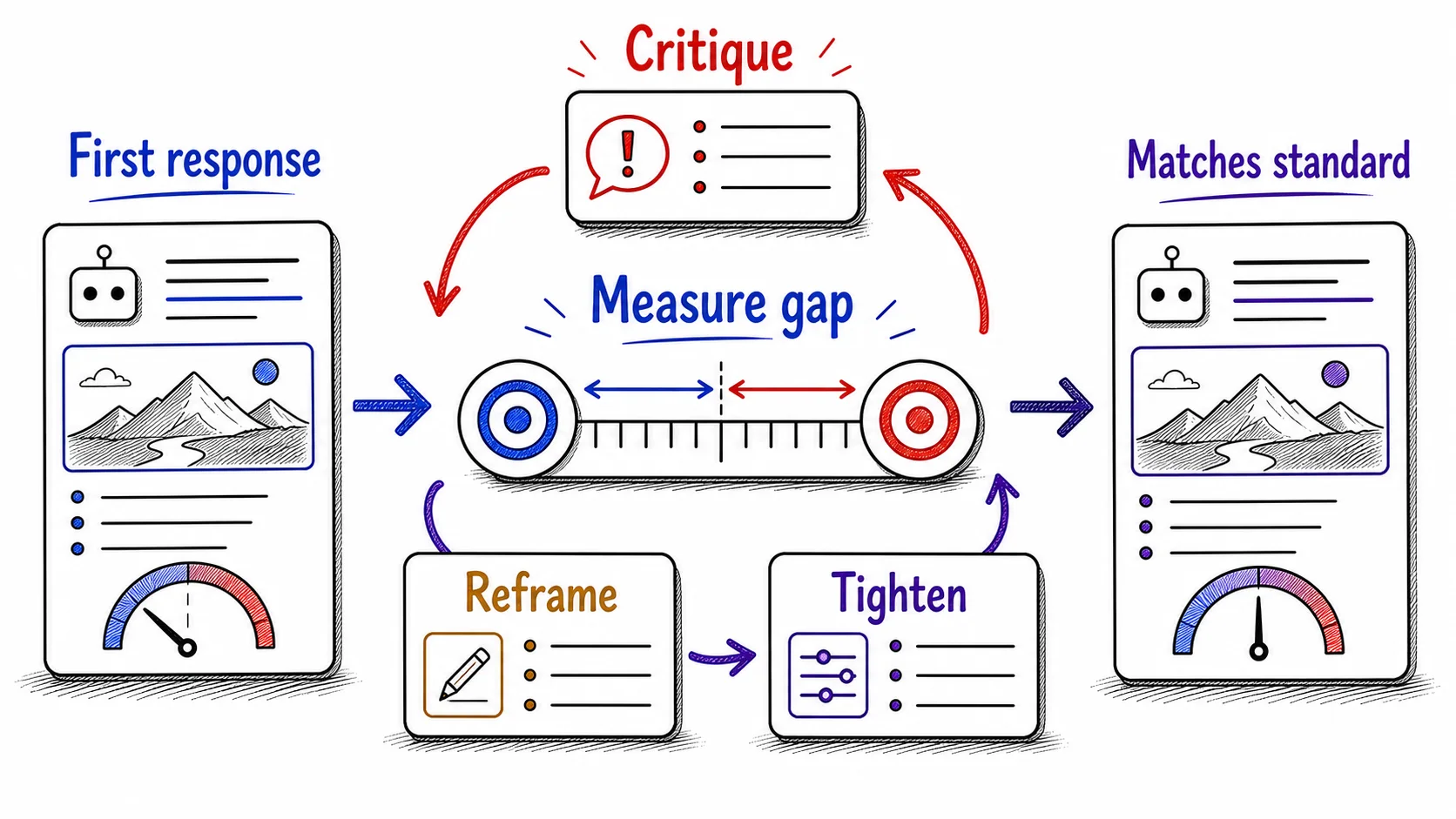
Read the first response as version zero, then improve from there
Here is the same idea named once, so you can hold it. A power user treats the first response as version zero, a draft that reveals the task as the model understood it, not the deliverable. The answer is coherent and instant, and those two qualities are exactly what make it easy to mistake for done. Reading underneath them, at what the model prioritized, assumed, and invented, is a habit experienced users build early.
There is a quiet bonus in this reading: a weak first response tests your own standard. If you can say in a sentence what is wrong with the output, your standard is clear and the next instruction writes itself. If you can only say that it feels off, the model can often help you name the gap: ask it to critique its own draft against your goal, or to list what it assumed that you never confirmed. Naming the gap is half the repair, and you can do that half by hand or set the model up to draft it for you.
The most experienced users iterate more, not less, which is the opposite of what most people expect. The intuition is that experts learn to fire off one perfect prompt and accept what comes back. The population data points the other way. The Microsoft data shows AI power users are 30% more likely to keep trying when a first response is poor. The Anthropic data shows the most experienced Claude users are more likely to iterate at all, even when the first response seems fine, because they are reading it as a measurement rather than waiting to be impressed. Skill shows up as more turns spent reading and correcting, not fewer.
The prose above has built the idea by feel. Here is the formal name.
Reach for a named follow-up move instead of improvising
You do not have to invent a follow-up each time. A small set of moves works across almost any task, and learning three or four of them well beats improvising every turn. Each move matches a different kind of gap, so once you have read the first response, you reach for the move that fits what you saw. They are durable because they are about what you want changed, not about which button to press; the same nine survive the move from typing to speaking to whatever comes next.
Not every follow-up is a correction. Some of the best ones are experiments: 'wouldn't it be better if we tried it this way,' or 'show me a version that takes this further than I asked.' Power users iterate to fix a gap, and they also iterate to play, using the model to stretch what they imagined the output could be. Compare, below, is one of those playful moves in disguise, since asking for three approaches often shows you an option better than the one you set out to write.
It helps to hold the nine in three families rather than as a flat list. Direction moves point the answer at the right target. Depth moves change how much the answer carries. Pressure moves stress-test what the answer is taking for granted. The table keeps all nine; the families are just how you remember which one to reach for.
Direction moves aim the answer at the right target
Reach for a direction move when the answer is about the wrong thing or pitched at the wrong reader. Reframe redirects when the model answered a different question than you meant, as in 'I want this framed around the business risk, not the technical details.' Adapt keeps the content but re-aims it at a new audience, as in 'Rewrite this for a board-level reader; remove implementation details and add financial impact.' Compare opens up options before you commit, as in 'Give me three different approaches to this problem with the tradeoffs for each.' All three change where the answer is pointed.
Depth moves change how much the answer carries
Reach for a depth move when the answer is the right shape but the wrong size or density. Simplify cuts complexity and jargon, as in 'Rewrite this for someone with no technical background, in half the length.' Deepen pushes a thin, generic answer toward specifics, as in 'This is too general; give me concrete examples with numbers and names.' Tighten removes the rambling and repetition a model defaults to, as in 'Cut this to the three most important points and remove everything a busy reader would skip.' Each adjusts how much the answer carries without changing what it is about.
Pressure moves stress-test what the answer assumes
Reach for a pressure move when the answer looks plausible and you want to find where it is weak. Critique surfaces problems the model will not flag on its own, as in 'What would an expert in this field criticize about this draft?' Challenge assumptions exposes what the model is taking for granted, as in 'What are you assuming about my situation that I have not confirmed?' Fact-check separates what the model can support from what it inferred, as in 'Which of these claims can you verify from the documents I provided? Flag anything you are inferring or guessing.' Each one tests the answer rather than reshaping it.
A solid starting set is Critique, Reframe, and Simplify, one from each family. Critique catches quality problems the model will not raise on its own. Reframe corrects direction when the model answered a different question than you meant. Simplify strips the jargon and filler that models lean on. Three moves, three families, and you can read most first responses and know which to use. Add the rest as the work asks for them.
Run the moves in sequence and the draft converges into a conversation
The moves are strongest in sequence, because a revision loop is a short conversation where each turn builds on the last. You do not fire all nine at once. You read the first response, send the move that fits, read what comes back, and send the next. Here is one full run on a single piece of work, so you can see the shape of three turns end to end.
Repair while the output converges, and change your approach the moment the same failure repeats. earns its keep only while each turn narrows the gap. When you can see the answer getting closer, keep going. When the same problem comes back after two clear corrections, more follow-ups tend to entrench the wrong direction rather than escape it. The signs of a stuck conversation, and what to do instead, come next.
Know when a fresh start beats one more correction
Sometimes a conversation anchors on a frame you cannot redirect, and the cleanest move is to start over. The model has settled on a reading of your task that survives every correction, so each new follow-up adds sediment instead of clearing it. Two signs tell you a reset will serve you better than another turn. The first sign is that the same core error returns after two clear corrections. The second sign is that the conversation has filled with corrections and counter-corrections until neither you nor the model can track the current goal.
When you see either sign, capture the state you want in one clear paragraph and start a fresh conversation with that summary as context. You do not have to write the summary by hand: ask the stuck conversation to state, in one paragraph, the current goal and what you have already settled, and you have your clean starting context. You can also set up the model to flag the loop for you, asking it to tell you when it is repeating itself or has lost the thread. Either way you carry forward everything you learned, now stated cleanly up front, and drop the tangle of half-corrections the model kept tripping on. Telling 'converging' apart from 'stuck' sharpens with practice, and that judgment is itself a power-user skill, the same one that tells you when to keep editing a draft and when to begin again on a blank page.
Encode the moves that keep working so the system runs the fix next time
The habit compounds over weeks, in two directions at once. After a few weeks of steady follow-up, your opening prompts get better, because you start to include up front the context you would otherwise have to add in turn two. Your follow-ups get sharper, because you build a vocabulary for redirecting the model and reach for the right move faster. This is the learning-by-doing effect the Anthropic data captures at the population level, felt in your own week.
When the same follow-up sequence keeps rescuing the same kind of task, stop retyping it and evolve the system that produces the task. First fold those moves into a reusable revision prompt, so the next first response starts closer to your standard before you touch it. Then climb a level: turn the prompt into a standard the model checks every draft against, and turn the standard into a skill the system applies on its own, so the fix you used to type is now built into how the work gets made. Keep these current as the models and your work change, since a move that fixed last quarter's draft can go stale. Each pass hands more of the repair to the system instead of keeping it in your head.
Practice the revision loop on something you recently accepted as-is
References
1 source- 1Economic Index: Learning Curves.
Anthropic · 2026
High-tenure Claude users are 'more likely to iterate on their work, and much less likely to delegate greater responsibility through directive use patterns.' The most advanced users use Claude more collaboratively, not more autonomously.
This overturns the intuition that experts automate more. They iterate more. The learning curve leads toward deeper collaboration, toward more involvement.