They package instructions, references, and standards into reusable workspaces so every session starts fully briefed
Chapter Progress: Early Draft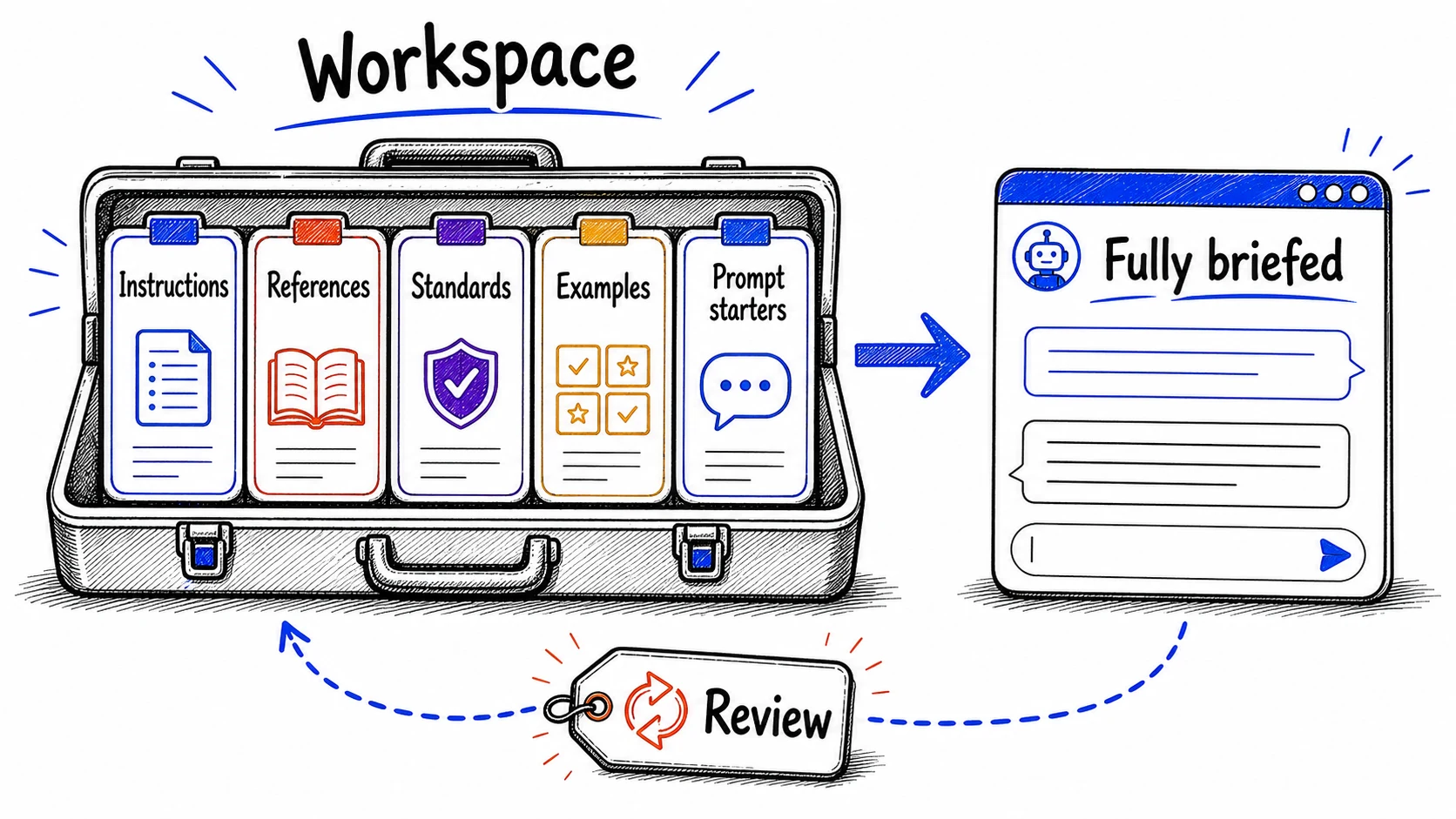
The prose above has built the felt idea: one prepared place that hands the model your full briefing at the start of every session for a task. Here is the name for it.
A is one move in a larger habit: encoding the context a task needs into a durable place so the work starts from a ready state rather than a blank one. The standing instructions, references, examples, and standards become persistent, so they no longer have to be retyped, and the next thing you tend to do is hand more off, climbing from individual prompts to a whole prepared environment. As of 2026 you build one inside a tool like a Claude Project, a custom GPT, or a CLAUDE.md instruction file, and the interface will keep changing under it, from a chat box to voice, then to glasses and earbuds, then to a brain-computer interface, then to whatever comes after. The encoding move survives every one of those shifts. Wherever you work with AI, however far its intelligence advances, you should not have to re-brief the same collaborator from a blank slate every time.
Workspaces gather five kinds of context, each carrying its own job
A well-built holds five kinds of context, and it helps to think of them as five named families rather than a flat checklist, because each family does a different job. Three families set the standing rules, and two families speed up the work itself. The standing-rules families are , reference documents, and quality standards. The work-speeding families are examples of good output and prompt starters. Hold those five and you hold the whole .
- carry the role, tone, format preferences, and recurring constraints. They set the baseline for every conversation, so the model starts in the right mode without you explaining it each time. For the client update, this is the standing instruction that you are a senior consultant writing to non-technical executives who need progress, risks, and decisions, kept under 400 words.
- Reference documents carry the style guides, briefs, scope documents, and process notes the work leans on. The model can read these without you pasting them into every prompt. For the client update, this is the project scope document and the client's communication-preferences note.
- Quality standards carry the mistakes to avoid, the things to always include, and the criteria a finished piece must clear. The model applies these checks on its own instead of waiting for you to remember to ask. For the client update, this is the rule to flag every risk with a severity level and to end with clear next steps.
- Examples of good output carry a few past deliverables you were happy with. The model learns your quality bar from concrete instances, which teaches it more reliably than an abstract description of what good looks like. For the client update, this is two earlier updates the client praised.
- Prompt starters carry pre-written prompts for the most common tasks in the workflow. You pick a starter instead of composing from scratch, and each one already includes the context, constraints, and follow-up instructions. For the client update, this is one starter that takes your raw notes and produces the formatted update.
The quality-standards family pays off most when each standard is testable. Asking for writing that is clear is a preference two readers could disagree about, so it gives the model nothing it can check. A standard like open with the decision, include three risks, cite every external claim, and end with next steps is an acceptance test anyone can verify in half a minute. When your standards are specific enough to check, the model can grade its own draft against them and tell you where it fell short, instead of either of you relying on a vague sense that it feels right. Testable standards also let one model judge another model's output against them, a technique the chapter on building learning loops develops.
A twenty-minute setup pays back across a month of Mondays
Watch the five families come together in one prepared environment for the Monday client update. As of 2026 you would build this as a Claude Project, and the same parts load the same way in a custom GPT or a project instruction file. The setup takes about twenty minutes once.
Set the prepared session beside the cold one to see what the buys you. Without the , every Monday you re-describe the client, re-paste the tone example, re-state the length, and hope you did not forget the risk-flagging step. With the workspace, you paste the notes and the rest is already in place, so what changes week to week is the week's actual news. A cold prompt can still produce a good update on a given Monday. The prepared version produces one reliably, from a shorter prompt, without leaning on your memory to rebuild the briefing each time.
Workspaces drift as you add to them, so plan to prune
A gets more specific every time you add to it, and past a point that specificity starts to fight itself. Each instruction, reference document, and quality standard you add makes the sharper for the case you added it for. Over months, those additions can begin to contradict each other. A tone rule you added for one strict client can collide with a warmer instruction you added for another. A reference document from the first quarter can describe a process that changed by the third. The model then tries to satisfy instructions that pull in opposite directions, and the output misses your bar in ways that are hard to trace back to a cause.
The maintenance move is a recurring review you hand to the model, not a line-by-line audit you do yourself. On a regular cadence, ask the model to read through all the and reference documents, flag anything stale or contradictory, and propose what to remove for your confirmation. You set up the review that notices drift and brings you only the decisions, so the work of catching contradictions sits with the system, not with your memory. The same review can run on the output: ask the model to grade a recent update against the testable standards and name where it fell short, which surfaces drift you would not have caught by feel.
The step that compounds is evolving the , not just cleaning it. When the review surfaces a fix you keep applying by hand, encode it: turn the recurring correction into a standing instruction or quality standard, so the next session starts with the fix already built in. That is the move power users make again and again, and it is partly a playful one. They keep asking what else the could carry, what a new starter prompt could try, what would happen if the standards were sharper, and each idea that works gets folded back in. A workspace that evolves this way does more each month than it did the month before, because every correction and every experiment becomes part of the prepared environment instead of a thing you redo.
Once a exists, power users often run several focused conversations inside or alongside it. A larger piece of work might use one conversation for research, another for critique, and another for drafting, all sharing the same instructions and reference materials. The next chapter extends this further into agents that operate inside a workspace and take action across your files and systems on their own.