They verify AI claims against sources because confidence and accuracy are unrelated in AI output
Chapter Progress: Early Draft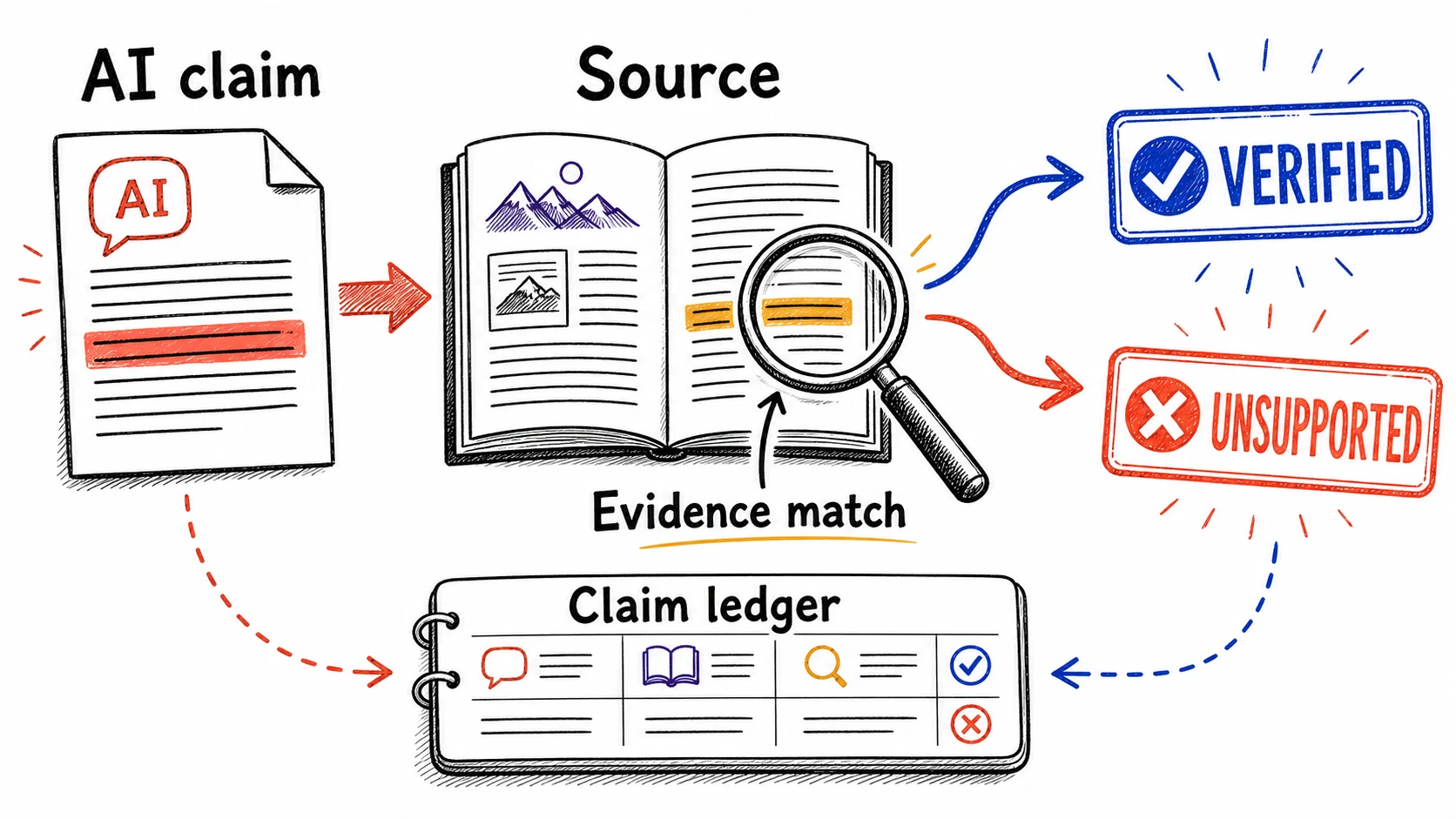
Fluency hides whether a claim is true, which is what makes AI research dangerous
Start with what the model is doing when it writes a research summary. It produces every sentence with the same even, confident voice. It does not mark which claim rests on a careful study and which it stretched from a pattern it has seen many times. It does not flag whether a citation points to a paper that exists or to one it assembled from fragments. It does not tell you where it is reporting a finding and where it is guessing. One uniform tone sits on top of claims of wildly different strength.
Picture the contrast on one task that will run through this chapter: you ask AI to research whether remote work raises or lowers the output of knowledge workers, because you are deciding what to recommend to your team. As of 2026 this looks like typing the question into a web-connected chat model and reading back a cited brief, and the interface will keep changing under it, to voice, then to glasses that carry world knowledge, then to whatever follows. One way of reading the brief is dangerous. You skim it, see citations and a clean claim that remote work lifts the output of knowledge workers across the board, and carry that line into the meeting as fact. The brief sounded sure, so you treated sure as true.
Do not trust the prose; audit the claim. The safe way of reading starts from a flat refusal to let tone stand in for evidence. The danger is not that AI sometimes sounds wrong. A model that sounds wrong is one you would catch. The danger is that it often sounds equally certain whether a claim is grounded, stretched, or invented, so its confidence is a poor guide to its accuracy, and you tell the two apart by leaving the brief and checking the source.
The stakes are part of why this chapter sits where it does. A generic email draft that misses the mark is forgettable; you rewrite a line and move on. A research brief with a fabricated citation can damage your credibility in front of the people you were trying to inform, send a decision the wrong way, or pass misinformation along to anyone who trusts your summary. The cost of a wrong claim is what decides how hard you check it, and that idea returns at the end as the rule that keeps verification from swallowing your day.
Source-grounded synthesis is a workflow you run, not a mode you switch on
As of 2026, several AI tools offer research-specific abilities: web-connected chat, deep-research modes, grounded search, document retrieval, and browser-based agents that open pages and read them. These can produce citation-backed reports that are far stronger than plain chat output, and the specific tools will keep changing while the move stays the same. A citation next to a claim is a lead to check, not a verdict. The output is a draft research brief, never a finished one, no matter how authoritative it looks.
The work of turning that draft into something you can stand behind has four moves. They are easier to hold as two pairs: first you shape what you ask for, then you test what comes back.
Shape the request so the answer is checkable
The first pair sets up the brief so verification is even possible. Frame the question precisely, because a vague question produces a vague answer you cannot check. 'What do we know about remote work productivity?' invites a wandering summary with nothing specific to test. 'What controlled studies since 2020 have measured the effect of remote work on the individual output of knowledge workers?' names a time frame, a study type, and an outcome, so the brief has to make claims sharp enough to confirm or deny. A precise question is also where you can play: chase a 'wouldn't it be cool if it could surface the studies I have not heard of' and let the model range wider than you would alone, as long as every claim it brings back stays checkable. Then ask the model to cite a source for every claim, and to mark any claim it cannot source as its own inference rather than a finding. That single instruction sorts the brief into two piles, sourced and inferred, before you read a word of it.
Test the answer against the claims that would change your decision
The second pair tests the brief once you have it. Verify the claims that would shape your decision, not every sentence in the document. Take at least the few claims that would change what you do, and for each one check three things: that the cited source exists, that it says what the brief says it says, and that the finding is not lifted out of the context that qualifies it. Then grade the evidence, because sources are not equal. A controlled, peer-reviewed study outweighs an industry survey, which outweighs a blog post, which outweighs a line the model inferred on its own. Mark each claim in your brief with the strength of the source under it, so a decision resting on a blog post is visibly weaker than one resting on a study.
A stronger version separates gathering sources from writing the summary. For high-stakes research, collect the sources first, read what they contain, and only then ask AI to synthesize a brief from those sources alone. This keeps the model from quietly blending verified evidence with plausible background knowledge it carries from training, which is the blend that produces a real-looking claim with no source you can open. You give it the evidence; it does the writing; the line between the two stays visible.
Now we have built the felt idea behind the chapter's term of art: a claim is trustworthy only when its origin is something you can open and read. Here is the formal name.
Open the cited source for every decision-shaping claim before you trust the brief
The finished brief looks authoritative: citations, numbers, and the polished voice of an experienced analyst. Every part of that look pulls you toward trusting it and moving on. The moment the brief looks most trustworthy is the moment verification earns its keep, because the appearance of rigor is exactly what a fabricated claim borrows to pass.
Return to the remote-work brief to see what verifying looks like in practice. The don't-verify path takes the headline claim at face value. The brief states that remote work lifts the output of knowledge workers across the board and cites a Stanford study, the claim is crisp, the sentence is smooth, so you write 'remote work raises knowledge-worker output' into your recommendation and consider it sourced. The verify path leaves the brief and opens the source. You click the citation, find the actual Stanford study, and read for the claim. The study does report a productivity gain, but for a specific group of call-center workers under one arrangement, not a broad effect across all knowledge workers. The model took a narrow, conditional finding and reported it as a general law. The citation was real; the claim was stretched past what the paper supports. You would never have seen that from the brief alone, because on the page the careful claim and the inflated one read identically.
Verification means checking that the cited source says what the model says it says: that the number, the finding, and the attribution all match the original. Power users make this a reflex, and they let the system carry as much of it as it can. They open the cited paper, read the relevant section, and compare its statistic to the one in the brief. They watch for the case where a model cites a real paper but pins a finding from a different paper onto it. And much of that comparison is delegable: you can ask the model to flag which of its own attributions it is least sure of, to quote the exact line in the source that backs each claim, and to mark any claim where the source line does not match. That turns the brief into something that surfaces its own weak points, so your reading concentrates on the few claims the system could not settle on its own.
The practice underneath all of this has a name from professional fact-checking, and it is the lens this chapter borrows. The prose has shown you the move on the remote-work brief; here is the term.
transfers from fact-checking to AI research with little change. Skilled fact-checkers do not judge a source by how credible it looks on the page; they move sideways, open the cited source in a new place, read the original, and compare it to the claim. AI research output rewards the same treatment: leave the brief, open the cited source, read the relevant section, and compare. That comparison is where you catch the embellished finding, the misattributed statistic, and the confidently wrong summary. The brief alone cannot show you those; the source can.
Fill one ledger row per claim and you cannot finish without opening the source
Telling yourself to 'verify the top three claims' is a good intention, and good intentions are exactly what a confident brief erodes. A replaces the intention with a structure you cannot complete without doing the verification. For any research brief that will inform a decision, you fill one row per decision-shaping claim before you act on the findings, and the row has a cell you can only fill by opening the source. Because you cannot fill the row without opening the source, you do the comparison by default instead of by willpower.
The ledger groups what you record into three kinds of information. The first kind frames the work: the question you asked and the decision it will shape, so a claim's importance is judged against a decision you face and not in the abstract. The second kind pins down each claim: the exact assertion from the brief and the source it cites, written down so the claim cannot drift while you check it. The third kind records your judgment: whether the source confirmed, partly supported, failed to support, or contradicted the claim, how strong that source is, what it says in your own words, and what you will now do with the claim. Below is a row you can copy.
The cost is small and the protection is structural. Plan a short verification pass for a five-source brief; in practice it is a handful of minutes per decision-shaping claim. You cannot fill the Notes cell without opening the source and writing down what it states, so the happens as a side effect of completing the row, not as a separate act of discipline you have to remember. The brief can no longer pass on polish alone, because every decision-shaping claim now has a row that either backs it up or exposes it.
The grades and notes you record outlast this one brief. The statuses and evidence grades you write are the start of a reusable rubric: the criteria that distinguish a trustworthy claim from a shaky one. The next brief on a similar topic starts from criteria you already trust. The real move is to climb a level: take the judgment you exercised by hand on this brief and encode it into a standard the system applies, so verification stops being a thing you remember to do and becomes a thing the workflow does. The chapter on building evaluation workflows with rubrics, examples, and judges turns these ledger statuses into the standard a judge prompt applies, so a step you do once evolves into a check the system runs every time.
Verification scales with consequence, which is what keeps it from eating your day. Every claim that will shape a decision deserves a row. A background claim that only adds color can be spot-checked. The choice is not 'verify everything' against 'verify nothing.' The working rule is to verify every claim you would be embarrassed to have wrong, which concentrates your effort where a mistake would be expensive and spends little where it would be cheap.