They build learning loops around AI workflows so every run improves the next one
Chapter Progress: Early DraftOne example runs through this whole subchapter: a weekly client update email, a short report a consultant sends a non-technical client about progress, risks, and decisions the client needs to make. As of 2026 producing it looks like describing what you want to a chat model and refining what it gives back, and the interface will keep changing under it, to voice, then to glasses that carry context about your week, then to earbuds, then to a brain-computer interface, then to whatever artificial superintelligence makes possible after that. One way of working tends to keep you resetting: each week you ask for the update, fix the parts that miss, send it, and start from scratch next week. The learning-loop way is to treat each week's fix as information about the system. The fix can travel when it lands somewhere durable, and the system itself can do much of that capture: you can ask the model to summarize what was missing and write it into the or the prompt your next request reads. The interface will keep changing. The loop carries across all of them, because pushing a system to do more, imagine more, and produce a more aligned result is what stays constant when the hardware does not.
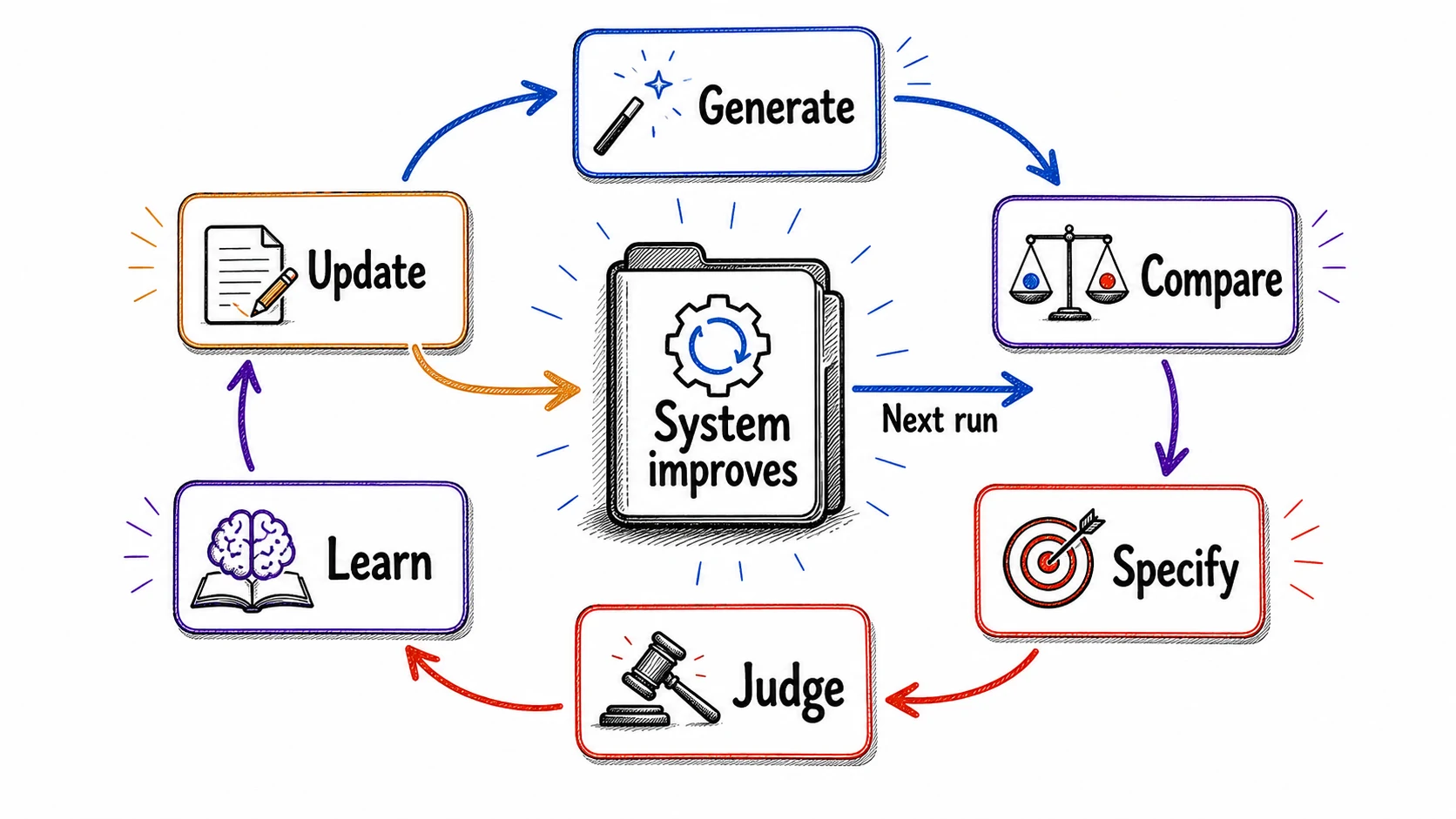
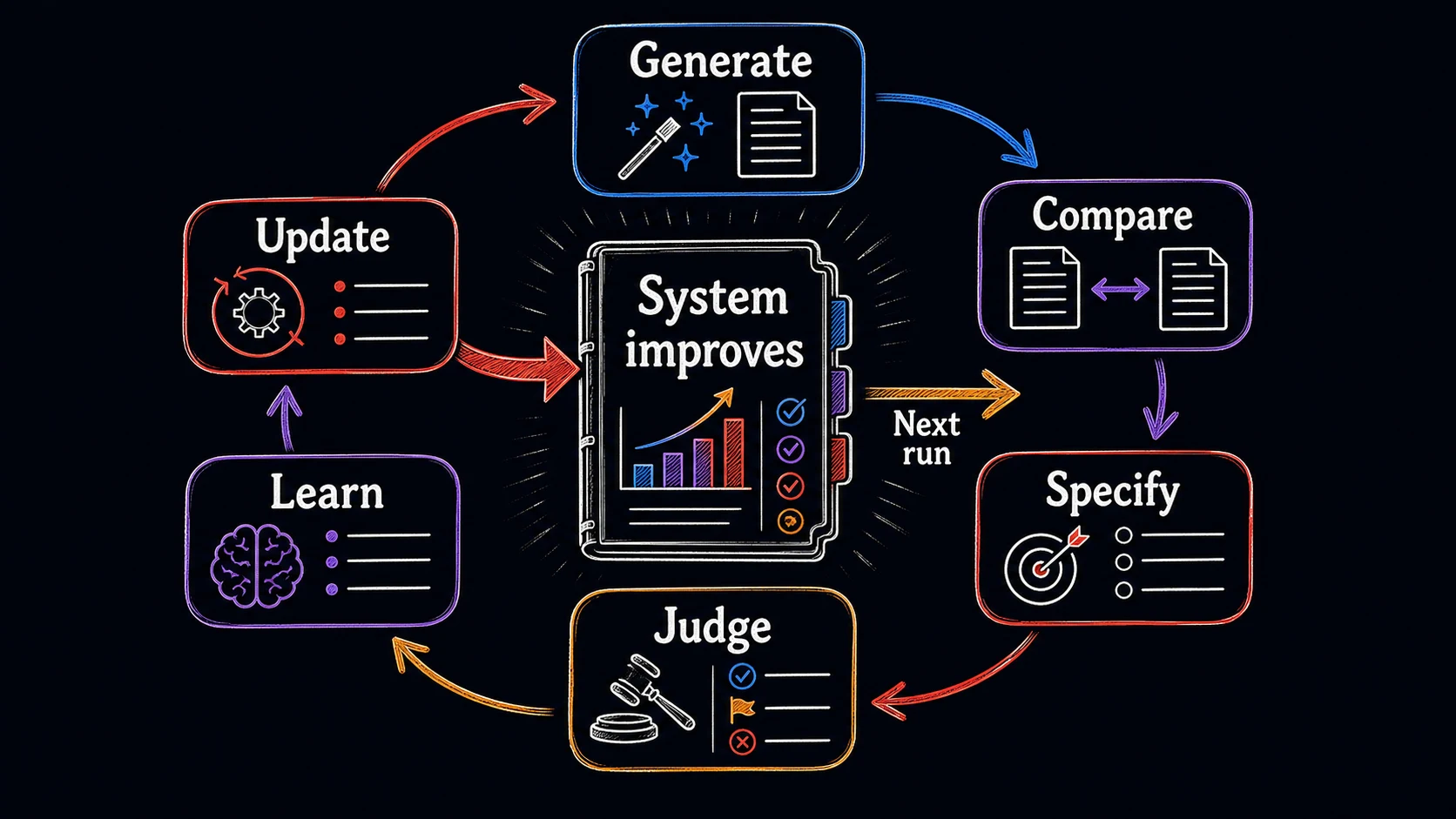
The loop has a simple shape, and the rest of this subchapter walks it one stop at a time: Generate, Compare, Specify, Judge, Learn, Update. You produce several candidate outputs and compare them to discover what you value. You name those values and build a judge that can score future outputs against them. You capture what you learn, especially where you and the judge disagree. You update the prompt, , examples, or workflow. Then you run it again, starting from the version you just improved.
A system that never updates its own instructions hits a ceiling
The chapters on reusable assets and on your gave you the prompts, specs, standards, and saved context you reuse. Think of those as a filing cabinet you built once. A filing cabinet that is never refiled slowly goes out of date. This subchapter adds the missing piece: the practice of judging output, capturing what you learn, and feeding it back into those prompts, specs, and standards so the cabinet stays current and the next run starts smarter.
Without that practice, your saved prompts and specs are frozen at the moment you wrote them. They work until the model updates, the task shifts, or your own taste sharpens. Then they quietly start producing output that feels 'off' in a way that is hard to place, because the instructions no longer match what you now want. A learning loop is what keeps your prompts, specs, and standards current. It is the difference between a system that improves as you use it and one that drifts the longer you leave it alone.
The organizational psychologists Chris Argyris and Donald Schön, who studied how people and organizations learn, drew a distinction that maps onto this directly. Single-loop learning fixes the action; double-loop learning fixes the framework that chose the action. Suppose your client update reads as a flat activity recap. The single-loop move is to rewrite this week's prompt so it leads with the decision. The output gets better once. The double-loop move is to change the itself, the standing description of what a good update is, so 'lead with the decision' becomes a requirement every future prompt inherits. Many people stay in single-loop mode, fixing one output at a time and never updating the framework, which is why the same kind of weak output keeps coming back. The loop in this subchapter is built to produce double-loop learning: feedback that changes the spec, rule, or workflow that chose the action, not only the output.
The prose above has built the felt idea: a cycle where each judged run writes a lesson back into the system that produces the next one. Here is the name for it.
You discover your criteria by comparing outputs, not before you start
The first time you set up a recurring task, you usually do not have a clean list of what makes the output good. You have a feel for it. You can look at a draft and say 'this feels wrong,' 'this one is closer,' or 'this version has the kind of precision I want,' without being able to say why in words a model could act on. That vague feeling is not a failure of preparation; it is the normal starting state for taste. Trying to write the rubric first, from the vague feeling alone, tends to produce vague criteria like 'be clear' that no one can score.
The usual advice is to define your criteria before you begin. A more reliable order is often the reverse. You generate several versions, then let the comparison teach you what you value. Produce five attempts at the client update, read them side by side, pick the strongest and the weakest, and ask what makes the strongest one work. The answer is where your criteria hide. You did not know in advance that you cared about 'opens with the decision instead of the background,' but seeing one version do it and one version fail to do it makes the criterion visible, and now you can name it.
The skill being built here outlasts any one task. Knowing how to pull criteria out of a comparison, rather than waiting until you can state them cold, is a move you reuse on every new kind of work. The first version of any recurring task starts as a vague feeling, and the comparison is how you convert that feeling into criteria a system can apply.
Examples carry your judgment further than adjectives can
Once you can name a criterion, you face a second problem: words like 'professional,' 'clear,' 'strategic,' 'warm,' and 'sharp' are weak cues. Two careful readers can look at the same client update and disagree on whether it is 'professional,' because the word points at different things in each of their heads. An adjective names a quality without showing what it looks like, so it leaves the judgment underspecified. Ask a model to make output 'sharper' and it has to guess which of a dozen things you mean.
An example closes that gap by showing instead of telling. A strong client update, saved and labeled, shows what 'leads with the decision' and 'specific dates instead of vague timelines' look like in one concrete artifact. A weak one, saved beside it, shows what a plausible-looking failure looks like, the draft that reads fine until you notice it never names a decision. Two examples, a strong one and a weak one, teach a model more about your taste than a page of adjectives. The strong one is the target; the weak one marks the edge the model has to stay clear of.
You do not have to build this library in a separate effort. It grows out of the comparison exercise you already ran. Every time you rank a batch of outputs and save the best and the worst, your example library gets one pair richer. Over a few weeks of doing this for a recurring workflow, the collection becomes a concrete portrait of your judgment that you can hand to any model or any judge.
Examples fall into a few named kinds, and it helps to know which one you are saving so the set stays balanced. The four families below each teach the model something the others do not.
A rubric tells a judge what to value. Examples show the judge what those values look like in a real artifact. Hand a model both a rubric and examples and you are giving it portable taste, your judgment in a form it can carry to new outputs. It can then evaluate fresh work with a consistency that adjective-only instructions cannot reach, because it has seen your standard rather than only been told about it.
An AI judge scales your taste so more output gets checked against it
Once you have criteria and a couple of examples, you can have one AI model read another model's output and score it against your standard. This is the LLM-as-judge pattern: a separate model reads the candidate output, scores it on your rubric, cites the evidence for each score, and explains its reasoning. As of 2026 this is common in AI research and increasingly practical for an individual setting up a single recurring workflow. A judge lets your taste check more work than you could read by hand, which is the move that makes evaluation scale past what your own attention can cover.
A judge prompt that works carries six parts, and the examples from your library are what make it yours rather than generic. The first three set up what to judge. A task definition says what is being judged and for whom. A list of priorities, in order, says which qualities matter most when they compete. A scoring rubric says how to rate each one. The last three steady the result. A gold example and a rejected example act as anchors, so the judge measures against your taste rather than a generic standard. A structured output format brings the scores back in a shape you can scan. And a confidence indicator lets the judge flag when it is unsure, so a shaky score does not read like a firm one.
A judge is worth using because it is fast, cheap, and consistent enough across many workflows. It is most useful when you treat its scores as a structured second opinion, not as objective truth. A judge that scores a 4 on 'leads with decisions' is giving you a calibrated opinion measured against your examples. It is not measuring a property of the text the way a ruler measures length. Read its scores the way you read a second editor's notes: seriously, and as input you reconcile with your own read to reach the better aligned call. When the two of you disagree, the disagreement is the most useful data the loop produces, and the next section is about how to use it.
When you and the judge disagree, the system is showing you what it has not learned
The runs that teach you the most are the ones where the judge and your own read point in opposite directions. A disagreement is not a problem to smooth over; it is the loop telling you exactly where the system is still blind. When the judge passes a draft you would reject, or rejects one you would keep, something the judge can see and you cannot, or the reverse, has come to the surface, and that something is the next thing to fix.
Disagreements come in a few recognizable kinds, and the useful part is that each kind points at a different repair. Once the kind is named, whether you spot it or you ask the model to classify the disagreement against these families, you know which piece of the system to touch: the rubric, an example, a criterion's wording, or a penalty. The four families below cover the common cases. Read each row as a pair: the disagreement on the left, the fix it calls for on the right.
Investigate the disagreement before you change anything, because the gap can sit on either side. You can ask a third model to interview both reads, lay out the case for each, and propose which one better serves the goal, so the investigation itself is partly delegable. Sometimes the judge surfaced a criterion worth adopting, and your rubric is what needs updating. Sometimes the examples were too thin for the judge to see why your preferred version works, and the examples are what need adding. Sometimes the investigation sharpens your own read and the judge was closer than you first thought. The aim is the call that best serves the result, from whichever read is stronger on this case, and whichever way it lands, the loop leaves behind a concrete improvement to whichever side was weaker.
Write each lesson into the one component that fixes it for next time
A lesson only compounds if it lands somewhere the next run reads. Closing the loop means deciding where the lesson lives, not just having it. After each judged run, ask yourself, or ask the model, which single part of the system should change so the next run starts from what you just learned. The answer is usually one of a small set of homes, and naming the right one is most of the work.
The components fall into three families by how durable the lesson is. The first family holds the standing definitions of the work: a memory or instruction that should persist across every future session, or a requirement that should be added, removed, or clarified in your description of the deliverable. The second family holds the working materials of a single workflow: a prompt instruction to change based on what worked or failed, an output to file as a gold, rejected, or boundary example, or a judge-rubric criterion to revise after a disagreement you investigated. The third family holds the shape of the process itself: the workflow's sequence, its review checkpoints, or its handoff points. Pick the most durable home the lesson genuinely belongs in, so a session-specific note does not get buried in a standing spec, and a real standing rule does not get lost in one session's prompt.
This is the practical link back to the earlier chapters. The reusable-assets and chapters built the filing cabinet; this subchapter builds the routine that keeps it current through structured feedback. The cabinet holds your prompts, specs, and standards. The loop is what refiles them as your model, your task, and your taste move.
A scheduled review beats waiting to feel inspired
A learning loop works best on a cadence. Left to inspiration, the review happens only when you are rested and curious, which is rarely the moment a workflow needs it. The fix is to stop relying on yourself to remember and instead set up a standing reminder, or a scheduled review prompt that runs the check on a date you picked once. The Deming Institute's Plan-Do-Study-Act cycle makes the same point for any improvement system: the scheduled study step is what turns scattered observations into systematic improvement, because it guarantees the looking-back happens at all.
The reviews live at four cadences, each handling a different scope of drift, from a single run up to whether a workflow should exist at all. The table groups them so you can set each one as its own standing reminder.
This cadence extends the rituals earlier chapters introduced from one session up to the whole system. The stress-testing chapter put weekly and quarterly capability re-tests on your calendar. The deliberate-practice chapter worked at the single-session level: reflect on one interaction and adjust on the spot. This subchapter scales that same reflex up to the system level, running Generate, Judge, Capture, Update, Schedule so the improvement keeps happening whether or not any single review finds anything dramatic.
Build the loop for one workflow before you build it for many
You do not set all of this up at once across every workflow. Pick one recurring workflow that matters, build the full loop around it, and let the practice prove itself before you spread it. The prompt below takes the gold and rejected examples you already have and assembles the rubric, the judge, the feedback-capture step, and the weekly review into one named, reusable workflow you can rerun, so the loop itself becomes a system you evolve rather than a one-time setup.
References
3 sources- 1Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, Chiang, Sheng et al. · 2023 · NeurIPS, 2023. https://arxiv.org/abs/2306.05685
Strong LLM judges can approximate human quality preferences at a useful level when given clear criteria. The study also documented systematic biases: position bias (preferring the first option), verbosity bias (preferring longer responses), and self-enhancement bias (a model rating its own outputs higher). Careful prompt design, blind ordering, and calibration mitigate these biases.
For power users, this means LLM-as-judge is useful as scalable, inspectable feedback, and it requires calibration: examples, blind ordering, and periodic comparison against your own human judgment.
- 2A Survey on LLM-as-a-Judge
Gu, Jiang, Shi et al. · 2024 · arXiv preprint, 2024. https://arxiv.org/abs/2411.15594
This survey corroborates the position and verbosity biases above and adds two that matter for setup: self-preference bias (judges prefer outputs from their own model family) and preference leakage when judges and generators share training lineage. It also reports that single-sample judgments are unreliable; multi-sample with temperature variation is required for trustworthy evaluation.
LLM-as-judge is a useful filter, not a verdict. Pair it with deterministic checks where they exist, use a different model family as judge to limit correlated errors, and treat disagreements between your human judgment and the judge's as the data that improves calibration fastest.
- 3Reflexion: Language Agents with Verbal Reinforcement Learning
Shinn, Cassano, Gopinath et al. · 2023 · NeurIPS, 2023. https://arxiv.org/abs/2303.11366
Reflexion demonstrated that AI agents can improve without changing model weights by reflecting verbally on feedback and storing those reflections in memory for later trials. Agents that maintained a running memory of lessons learned from failures outperformed agents that simply retried from scratch.
For power users, this translates to a practical principle: your AI system can learn operationally by improving the artifacts it consults. When you update memory files, specs, examples, rubrics, and workspace instructions, the next run reads the improved versions and starts from them, without retraining the model.