They treat experimentation as personal R&D because best practices lag behind the frontier
Chapter Progress: Early DraftWhen a model updates, two things shift at the same time. Some tasks that used to fail start working, because a capability that was missing arrived. Some approaches that used to work start producing different results, because the model now reaches a step differently. Testing your own workflows against the current model is how you tell which is which. Waiting for a tutorial to sort it out for you means learning it late, after the edge has moved again.
The map keeps drifting because capability builds on itself. Each new capability opens the set of moves that are now within reach from where you stand, what the biologist Stuart Kauffman calls the adjacent possible: the things that become possible the moment something else does. A model that can now read a long document well makes summarizing it, comparing it against others, and drafting from a stack of them newly reachable. Each of those, once reachable, opens still more. Capability compounds, so the edge moves faster than any single guide can follow, and your own experiments are how you keep your map current with it.
Power users alternate between heavy use and deliberate experiments. Heavy use applies what you already know, which is where most of your AI work gets done. Experiments extend what you know, which is how the heavy-use part keeps getting better. The two feed each other: an experiment that confirms a new capability changes how you run the everyday work, and the everyday work surfaces the next thing worth testing. Neither replaces the other.
Not every experiment starts from a problem; many start from "wouldn't it be cool if." Some of the best discoveries come from playing with a wild idea, starting a project you have no proven method for, or asking the model to do something just to see how far it can go. Curiosity and a sense of play are one of the real engines of improvement, sitting right alongside inspection, strategy, and the routines you set up. You can use AI to expand your own imagination here: ask it to brainstorm a dozen uses you have not thought of, then test the two that excite you most. The budget below keeps the disciplined experiments on the calendar; it is meant to protect that play, not crowd it out.
Treat experimentation as a budget you plan, not a free habit you hope for. You are spending time, attention, compute, and cost, and naming that spend lets you protect it instead of leaving it to whatever is left after the day. A scheduled 15-minute weekly test built around one specific question keeps the spend deliberate. Open-ended tinkering with no question is the part of the budget that drains without returning a result you can act on. Spend enough to keep the map current, not so much that experimenting becomes the work instead of the thing that improves it.
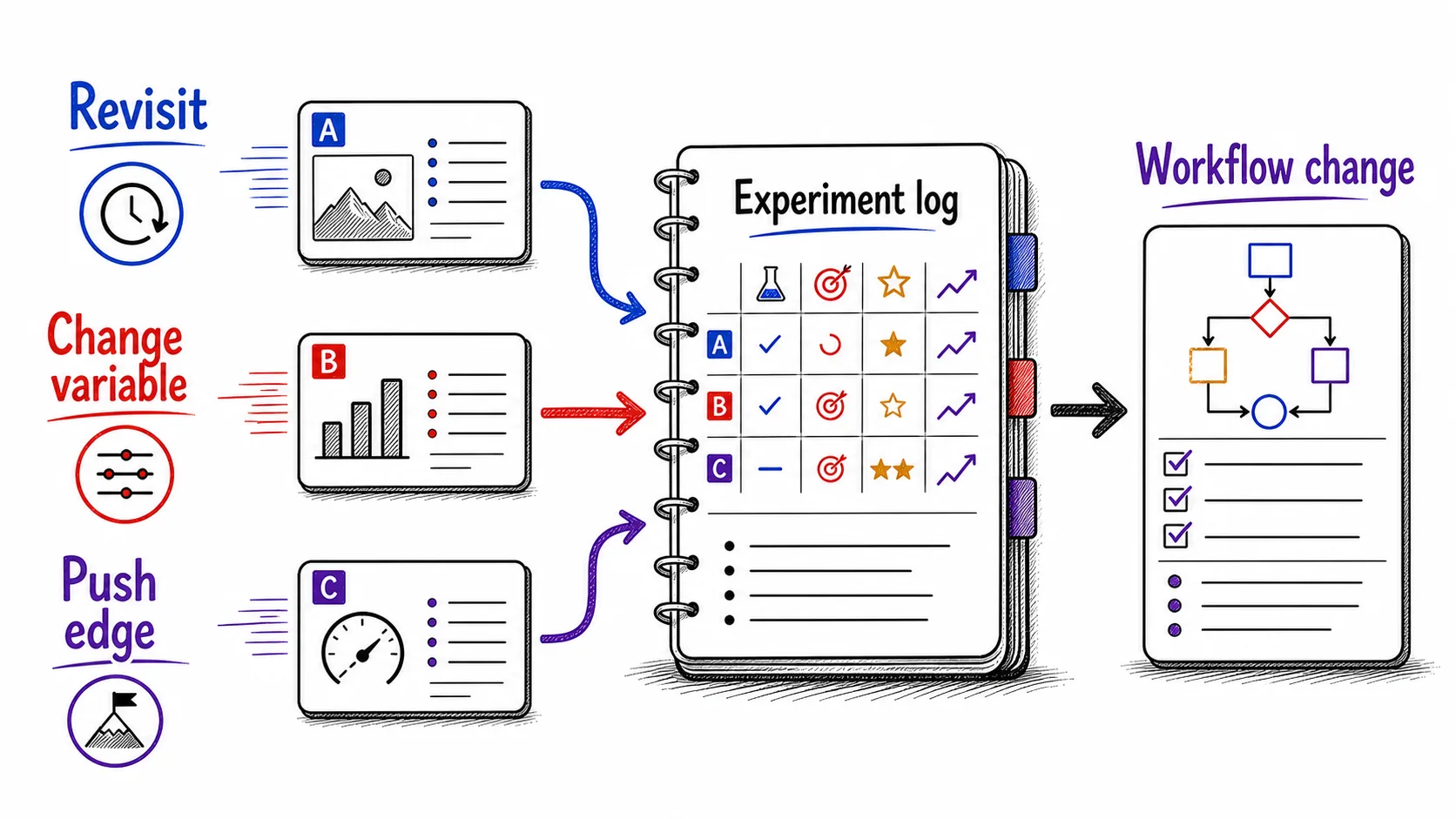
Run three kinds of experiments to keep your current
The tests you run fall into three kinds, and naming them lets you pick the right one for the question you wrote. Revisiting checks an old verdict against a new model. Varying changes one part of a workflow that works to see if a better version exists. Pushing takes a task to the edge to find where AI currently stops. Each kind answers a different question about the frontier, and together they keep the whole map current rather than only the corner you happen to use most.
Revisit a task you once decided AI could not handle. Keep a short list of tasks you tried, judged AI could not do, and set aside, then return to one on purpose. Some of those calls still hold. Some are stale, because a task that failed six months ago can work today after the capability that blocked it arrived. The test is direct: take one dismissed task, give it your current best prompt and context, and watch what happens. When it now works, update your mental model and have the AI capture the winning approach as a reusable prompt or workflow, so the gain carries forward instead of staying a one-time output. When it still fails, record the specific way it fails so you can retest it quickly after the next model update.
Change one variable in a familiar workflow. Workflows that work tend to harden. You run the same prompt sequence because it does the job, and you stop checking whether a different approach would do it better. The test is to take a workflow you run often and change exactly one thing, so you can tell what the change did. The variable you change comes from a small family of options: use a different , meaning a faster or more capable version of the model; supply the same context in a different format; split the task into more steps, or combine steps you used to keep apart; add a pass where the AI reviews its own draft against your criteria; or remove a step you assumed was necessary. Change one of these, hold the rest steady, and compare the result against your usual output.
Push one task to the edge of what you think the model can do. A test at the edge shows you where AI currently stops, which is the fact your map most needs and the one heavy use never surfaces. Take a task at the limit of what you believe AI can do and give it your strongest prompt, full context, and the most capable model you have. If it works, you have found new ground, so have the AI encode the move that got you there as a prompt, standard, or workflow you can run again. If it fails, you have a precise point of failure to record and retest later, which is itself a result: you now know where the edge sits for that task instead of guessing.
Keep the record, because skill compounds only when you inspect what you tried
Skill does not compound unless you inspect your experience and write down what it taught you. Run a test, learn something, move on, and the lesson fades by next month; the experiment is then an experience you had rather than a capability you keep. The experiment log is what converts the one into the other. It holds what you tested, what surprised you, what you would change, and when to retest, and it becomes your own record of the frontier as you have met it. Without the log, you re-learn the same lessons every time the model updates, paying the cost of the experiment again and keeping none of the return.
Four fields per entry carry the weight, so the log stays small. An entry records the hypothesis (what you expected), the test (what you did), the result (what happened), and the implication (what you would change in your workflow). The hypothesis is the field beginners skip and the one that makes the log worth keeping: writing down what you expected before you run the test is what turns a surprise into a lesson, because you can see the gap between what you predicted and what happened. Ask the AI to set up the template and to draft the hypothesis field from each test you describe, so the record costs you almost no extra effort.
- Hypothesis: what you expected to happen, written before you run the test.
- Test: what you did, specific enough that you could run it again the same way.
- Result: what happened, including the way it failed if it failed.
- Implication: what you would change in your workflow because of the result.
Over time the log shows patterns no single test reveals. Which kinds of tasks improve with model updates, which stay stuck across several versions, and where the model's strengths and limits keep their shape: these are visible across many entries and invisible inside any one. You do not have to spot them by reading every line yourself. Once the log holds a dozen entries, paste it back to the AI and ask it to find the patterns, group the tasks by whether they tend to improve or stay stuck, and flag the verdicts worth retesting. A verdict you would have trusted from one session ('AI is bad at this') often turns out to be one data point, and the log, read this way, is what lets you tell a durable limit from a one-time miss.
The loop does not end at the log entry; it ends by evolving the system. When a test confirms a new capability, do not just store the prompt that worked. Hand the move up a level: encode it into something a process can run without you, a reusable prompt, a standard the output gets held to, a rule, or a workflow, folded into the library you already use. That is the abstraction jump, the move that turns a thing you can now do into a thing the system now does for you. The next time the frontier moves, you test against that growing library instead of a blank prompt, and each confirmed discovery raises the floor for the work that follows. The mechanics of building and reusing that library come later, in the chapter on reusable AI assets; here the move is only to capture the win and lift it into the system so it does not evaporate.
Watch where this principle goes wrong on a setup you might build. Picture building your own personalized software, a setup tailored to how you live and work, with a morning brief, a short rundown of your day, as one piece of it. The interface will change over time, from typing into a chat model as of 2026, to voice, to glasses that carry world knowledge, to earbuds, to a brain-computer interface, and on to systems far more capable than today's; the move stays the same. The don't-apply path is to design the whole setup this month from last year's idea of what AI could do, lock in the workflows that fit that idea, and never test them again, so the setup quietly ages while the models underneath it get more capable. The do-apply path is to keep one running question, what just became reachable that was not before, and run a small weekly test against your own setup. When a model update makes a step you used to do by hand newly automatable, you find it in a 15-minute probe, not a year later, and you fold the new capability in before the gap between what you built and what is possible grows wide.
References
1 source- 1; the adjacent possible is developed further in Kauffman's later work on biological and technological evolution.
Stuart A. Kauffman, Investigations. Oxford University Press · 2000
Kauffman describes the adjacent possible as the set of states one step away from where a system currently is. Each new combination that gets realized expands that set, opening further combinations that were not reachable before. Possibility grows from possibility, so the space of what can happen next keeps widening as the evolving population explores it.
AI capability moves the same way. Each new thing a model can do makes a further set of tasks reachable, so the frontier is not a fixed line you learn once. Experimentation is how you stay current with an edge that keeps moving, rather than working from a map drawn before the last few capabilities arrived.