They own their AI infrastructure: prompts, specs, and workflows that work across any model or provider
Chapter Progress: Early Draft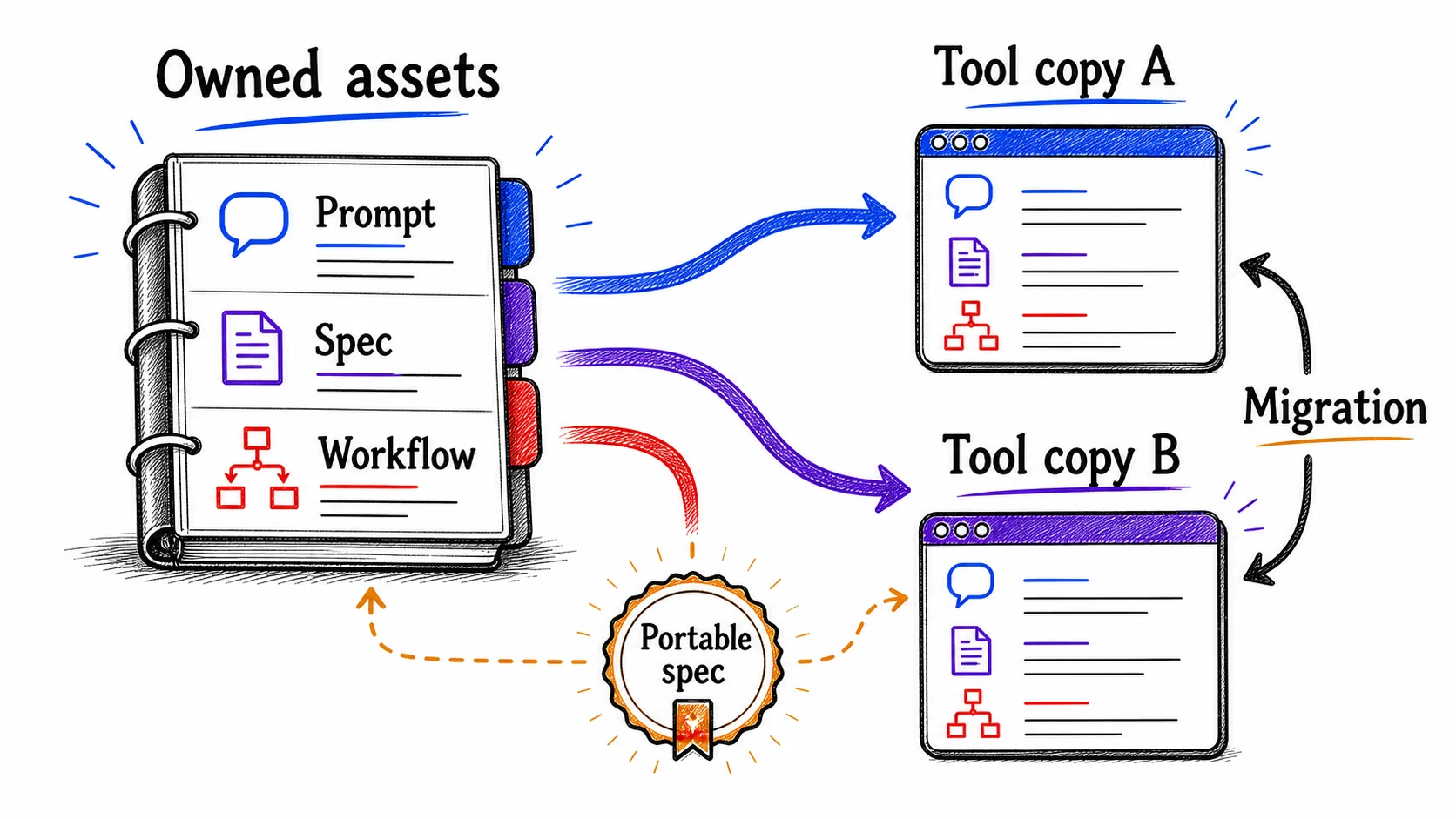
The difference shows up the day you switch. When your expertise lives in plain-text files you control, moving to a new model is a migration: you copy your prompt into the new tool, adjust a few details, and keep going. When it lives only inside a proprietary format, moving is a loss: you start over, rebuild from memory, and hope you remember what you tuned. The prose so far has built the idea by feel. Here is the name for the thing you are protecting.
Describe the outcome you want, not the tool feature that delivers it
A common way a prompt gets locked to one provider is subtle: it names a feature instead of the result that feature produces. Name the result you want, and the prompt travels; name the vendor's button, and the prompt stops working the moment the button does. A model can rename a mode, retire it, or never have offered it, and a prompt that asked for the named mode breaks. A prompt that asked for the underlying result tends to keep working, because most capable models can produce a result even when they label the feature differently or not at all.
Watch the same request written both ways, on one concrete task: getting AI to analyze a long document and show its reasoning before it lands on a conclusion. The locked version reaches for a named feature. It says 'use this provider's extended-thinking mode to analyze this document.' That sentence works only where a feature with that name exists. Move it to a model that calls the same idea something else, or that simply reasons step by step without a special mode, and the instruction has nothing to grab. The portable version names the result instead. It says 'analyze this document with step-by-step reasoning, and show your work before the conclusion.' That describes the result you want, visible reasoning leading to the answer, so most capable models can deliver it, and the second-model test below is how you confirm a given one does. As of 2026 the locked phrasing points at a toggle in a chat interface; when the interface becomes voice or glasses, the toggle may be gone, and the outcome-based request still makes sense out loud.
The same trap hides inside model-specific prompting tricks. A prompt built around one model's formatting quirk, a magic phrase, an exact header it happens to respond to, a token pattern that nudges it a certain way, can degrade the moment that model updates, and it rarely survives a move to a different provider. A prompt that states what you want plainly, gives an example of good output, and lists the quality criteria the result must meet, works across models because it communicates intent rather than exploiting one model's wiring. The clearer your instruction is about the outcome, the less it depends on any single model behaving the way it does today.
Keep the workflow design separate from the tool that runs each step
A single prompt is one move. A workflow is the plan that strings several moves together, and it holds things no prompt holds on its own: the order of the steps, the points where you decide what to do next, the quality checks along the way, and the handoffs from one step to the next. Write the plan down once as a sequence of outcomes, and the plan tends to outlive the tools that happen to run its steps. A workflow that reads 'load the context, then generate the analysis, then verify the claims, then format it for the audience' describes what has to happen at each stage without naming who does it, so it keeps working no matter which tool performs each step.
Watch the document-analysis task grow into a small workflow to see the move. The fragile way ties the whole sequence to one tool. You build the document analysis as a saved setup inside a single provider, with its named mode here, its integration there, the steps wired into that one interface, and you never write the plan down anywhere else. When the tool changes or a better one arrives, the sequence has nowhere to live, so you rebuild it from memory. The portable way keeps the plan in a file you own. You write the four steps as outcomes in plain text, load the context, produce step-by-step analysis, verify the claims, format for the reader, and let any tool run any step. When a new tool turns out to verify claims more reliably, you swap that one step to the new tool and leave the rest of the plan untouched, because the plan was never welded to the tool. As of 2026 that plain-text plan is a short markdown file you paste into a chat window step by step; when the interface becomes voice or an agent that reads the file directly, the same four outcomes still describe the work, because the plan names what has to happen rather than where you type it.
This mirrors a principle that has held in software for a long time: the architecture outlasts any particular implementation. A design written as a sequence of outcomes survives the tools that come and go beneath it, the same way a well-planned building outlasts any one contractor. Map the analogy carefully so it earns its place. The source is a building plan; the target is your workflow design; the shared structure is that a stable plan lets you replace the people or tools carrying out each part without redrawing the whole thing. Where the analogy stops, drop it: a building is finished once, and your workflow keeps evolving as better tools appear, which is the point of keeping the plan separate in the first place. For the full mechanics of packaging a setup so every session starts ready, the chapter on building reusable workspaces goes deeper than this portability lens does.
Test a critical workflow on a second model to find the dependency before it finds you
You can believe a workflow is portable and be wrong, because the only proof is running it somewhere else. The plainest portability test is to ask whether your most important workflow still runs on a second provider. Take your best prompt, load it into a different model, run the same task, and compare what comes back. You can have the AI run both and report where the two outputs diverged, so the comparison itself is delegated rather than done by eye. If the quality holds, the work is portable in fact, proven by a run and not assumed. If it slips, the test has surfaced a hidden dependency on the first provider, and finding it now, on a test you chose to run, often beats finding it the week the first provider changes and you are stuck.
Running the same workflow on two models surfaces something the single-provider version never could: where each model is strong and where it is weak for this exact task. You do not have to track that by hand. Ask the AI to compare its two runs and report where they diverged, then turn that comparison into a routing rule the system follows next time, so the analysis step goes to the model that reasons most clearly and the formatting step goes to the model that follows structure most reliably, instead of leaning on one provider out of habit. That is the move that matters: the test does not end with a result, it ends with an upgraded system, a routing rule encoded once so the choice runs itself afterward. The chapters develop this kind of model matching in full; the portability test is the small move that starts building the map.