They turn every AI interaction into a compounding improvement
Chapter Progress: Early DraftWe may recapitulate by saying that the origin of thinking is some perplexity, confusion, or doubt.
You ask AI for something, get back a draft that is almost useful, and fix the rest by hand. It works. Next week you ask for the same kind of thing and fix the same rough edges again, because the fix you made the first time lived only in your head. The correction was never written down, so it could not travel to the next request. That reset, back to zero every time, is the default way of working with AI. There is another way to work, where each interaction leaves something behind that makes the next one start higher, and where you keep asking what else this setup could do.
Picture the alternative as one short circuit. You ask, you compare what came back against what you wanted, and instead of only fixing this output you write down the one thing that was missing, in a place your next prompt can reach. The fix stops being a private chore and becomes part of the system that produces your work. Run that circuit on the requests that recur, and each turn starts a notch above the last.
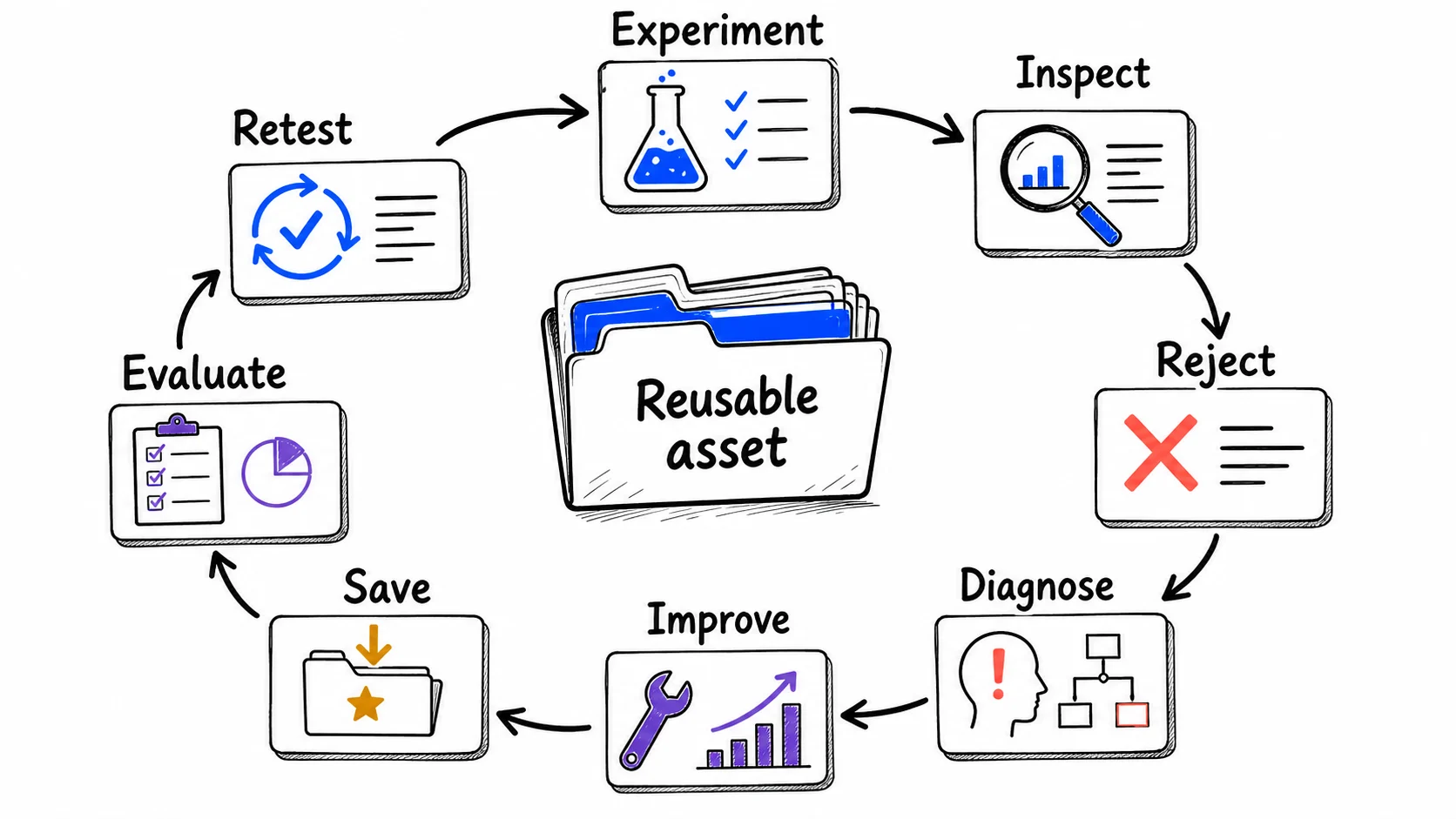
Read every output as two things at once
The first sign that you are getting serious with AI is that weak outputs start becoming useful to you. A casual user treats a weak answer as a disappointment: they regenerate, reword, complain, or move on. A power user reads the same answer as evidence. Something was missing, the goal was underspecified, the model lacked context, a standard was implicit, the task was too broad, or the bar for evidence was unclear. Each weak output points to a gap in the system that produced it.
AI rewards several old habits at once, in a very new interface. One is curiosity and play: the constant wouldn't-it-be-cool-if, the fun experiments, the new projects, using AI to stretch your own imagination past what you would have pictured alone. Another is inspection and evaluation: act, look closely, compare, diagnose, adjust, try again. Educators would recognize part of this as reflective practice. Psychologists would recognize part of it as deliberate improvement. Engineers would recognize it as feedback control, a system that reads the gap between what it produced and what it should have produced and corrects. Software people would recognize it as turning bugs into specifications. These run together rather than in rank order. The playful side keeps asking what else is possible; the evaluative side closes the gap between what happened and what should have happened, and keeps the correction so you do not reopen the same gap next time.
AI ability tends to be uneven across tasks, users, and contexts, which is why the loop matters. On some tasks AI can sharply improve speed and quality. On nearby tasks that look just as reasonable, it can make confident users worse. The loop is how that boundary gets mapped, where the model has caught up and where it has not, by running an evaluation on your own work rather than guessing from a general reputation. You can set up the system to run those checks and report what it found, instead of testing every case by hand. The deeper skill is learning how to monitor a system that does not announce its own limits.
So the question is not whether to use AI. The better question is what kind of loop you are building when you use it. If every interaction ends the moment you receive an output, your practice resets to zero. If every serious interaction leaves behind a reusable improvement, your practice compounds. A rejection becomes a style rule. A fabricated claim becomes a verification step. A vague answer becomes a context checklist. A missed constraint becomes an acceptance criterion. A result you liked becomes a saved prompt, rubric, example, or workflow.
The prose above has built the felt idea: a recurring cycle where each turn leaves behind something the next turn can use. Here is the formal name.
A small everyday example shows the contrast. Say you want AI to write you a short morning rundown of your day. As of 2026 that looks like describing what you want to a chat model such as Claude Fable and refining what it gives back. The interface will change, to voice, to glasses that carry world knowledge, to earbuds, to brain-computer interfaces, to systems far more capable than today's. The loop will not. A person who does not think this way re-describes their whole situation every session, accepts whatever comes back, fixes the parts that do not fit the day, and re-describes it all again tomorrow. A person who does think this way writes each correction down as a saved instruction, a standard, or a workflow the next request can read, so they are improving the thing that produces the rundown rather than rebuilding it from scratch.
Separate the single turn from the habits that act on it
Two different things share the word loop, and keeping them apart makes the rest clear. The cycle is what happens on a single turn: the eight stages in the diagram above, run once. The practices are the durable habits you bring to those stages, the principles this chapter develops. A practice is not a ninth stage. It is a way of handling the stages well, and one practice can act on several of them.
Map the practices onto the cycle and the relationship is easy to hold. Raising your standards acts on the inspect and reject stages, where you compare the output to what you wanted and decline what falls short. Improving the conditions, not only the output, acts on the diagnose and improve stages, where you fix the prompt or the context rather than the result. Turning failures into specifications acts on diagnose and save, where a frustration becomes a written rule. Treating use as experimentation acts on experiment, where you test what is newly possible. Supplying the right context acts on improve, where you give the model the distinctions the task needs. Verifying in proportion to stakes acts on evaluate. Saving what you learn acts on save, the stage that keeps the gain. Climbing to supervise acts on evolve, where a process you have mastered becomes something you direct from a level up.
is the connective tissue, not another stage. It is awareness of your own goals, expectations, and intent, clear enough that you can put what you silently know into words the model can use. Much of what makes your work good is tacit: a doctor reads a symptom an untrained eye would walk past, and could not list every rule that let them see it. is the discipline of surfacing that knowledge and saying it, so it can become context, a standard, or an example the system carries. This is a communication skill, and it stays useful no matter how the interface changes. Even with a brain-computer interface, you still have to focus attention on what you actually want and notice and name when something is off. That same awareness is what lets you turn a step you do by hand into a step a process can run.
Eight principles develop across the chapters ahead
Read the eight as a map of where the book is going, not eight things to absorb now. The practices that act on the cycle come down to eight principles, and the saving principle now has its own subchapter, so the move that keeps your gains gets the room it needs. Each later part develops one principle through a practical project and goes deeper on it.
Raise your standards with every interaction so quality ratchets up
When a model lacks the distinctions your task needs, it falls back on high-probability, generic patterns. Asking more emphatically does not move it off that center. Power users name the specific patterns of generic output, then turn each rejection into a standard the next output must clear. Every time you decline weak output and write down why, the bar rises and stays risen.
Improve the conditions that produced the output, not only the output
The prompt that compounds asks the model to help design the system that does this task well, applied after a task you will do again. This is : asking AI to sharpen your prompts, draft a rubric, name the missing context, surface the failure modes, turn a useful exchange into a , or shape a workflow. The same move runs backward too, starting from a result you admire and asking what made it work. Either direction improves the system that produces the output, so each interaction raises the floor for the next one.
Turn a failure into a specification by naming what the input was missing
A frustrating output points at an unstated requirement. A weak draft reveals a missing style rule. A fabricated claim reveals a missing verification step. A tone failure reveals a missing preference note. A missed constraint reveals a missing acceptance criterion. Power users write each one down once, so the frustration becomes a reusable instruction, specification, or standard the system carries forward.
Run experiments at the frontier because your map of what is possible decays
Best practices are lagging indicators. They describe what was possible when someone wrote them down, and capability keeps expanding whether or not you act, so the map goes stale on its own. Your own experiments are how you learn what is possible now. Power users treat use as personal research and development, spend an experimentation budget of time, attention, and cost, and test at the edge of what reliably works.
Supply the distinctions that decide whether the task succeeds
Useful collaboration runs on shared understanding, and a model will not build that the way a colleague does, so you supply it first. The skill behind giving AI context is knowing what you know, prefer, assume, and expect well enough to make it available. Power users treat prior conversations, personal preferences, workflows, examples of good and weak output, error logs, decision history, and audience expectations as the distinctions a task turns on.
Verify in proportion to what an error would cost
Once you have standards, AI can help apply them, which lets you check quality without reading every output by hand. A judge prompt extends your taste across more work. Evaluation builds in layers: your own judgment as the first pass, written criteria as the second, and AI-assisted checking as the third. The skill is matching how much you verify to what an error would cost, and trusting the model where it has shown competence on this specific kind of task, not in general.
Save what you learn so expertise compounds instead of resetting
Capture the decision that improved the output in a form the next interaction can read. A is one form of saved work. Specifications, rubrics, checklists, judge prompts, examples you want copied, examples you want avoided, style guides, saved memories, workflows, error-mode notes, and model-selection notes are others. The principle holds across all of them, whether the sharper call came from you or the model. This principle has its own subchapter because saving is the stage that turns a good turn of the loop into a lasting gain.
Automate the level you can describe and supervise from above
Other principles improve your skill at a given level; this one moves you to the next level. Once you can reliably decline weak output, improve the conditions, turn failures into specs, and verify results, you package those steps into a system and shift your attention to directing it. You can hand off a task only to the degree you can describe it, and AI increasingly helps you describe it, so this climb runs through making tacit competence explicit. The prompt you wrote once becomes a saved template, the template becomes a workflow, and the workflow becomes a standing instruction the AI follows while you supervise the work and stay accountable for it. The ground floor never closes. A beginner can run one honest turn of the loop today, and the climb is the horizon, not the entry fee.
Each chapter ahead is one turn of the loop
Each chapter develops one principle through one practical project. The opening chapters introduce the eight principles and give you a working version of each. The chapters that follow go deeper: choosing and working with models, breaking complex tasks into steps, calibrating trust, building reusable prompts, rubrics, and saved standards, and redesigning workflows. By the final chapter you are running the loop at higher levels, designing and supervising the systems that do work you used to do by hand.
References
1 source- 1Navigating the Jagged Technological Frontier
Dell'Acqua, McFowland, Mollick, Lifshitz-Assaf, Kellogg, Rajendran, Krayer, Candelon, and Lakhani. · 2023 · Harvard Business School Working Paper 24-013, 2023. Field experiment with 758 BCG consultants. Conditions: no AI, GPT-4, and GPT-4 with a prompting overview.
On tasks inside the AI frontier, consultants using GPT-4 completed 12.2% more tasks and worked 25.1% faster, and produced results rated more than 40% higher in quality than the group without AI. On tasks outside the frontier, consultants using AI performed 19 percentage points worse than those working without it. The boundary between inside and outside was invisible to the consultants before they tested it.
The jagged frontier is the reason the compounding loop matters. Without testing on your own tasks, you cannot see where AI helps and where it hurts. The loop builds that map through repeated experimentation, evaluation, and recalibration.