They build evaluation loops before they scale delegation
Chapter Progress: Early Draftrefers to the correspondence between a person's trust in the automation and the automation's capabilities.
Naming what you just felt makes it usable. Researchers who study people working alongside automated systems call the coworker move trust : matching how much you rely on a system to the competence it has shown for the task at hand, not to how sure it sounds (John D. Lee and Katrina A. See, 2004). The same idea, stated as a definition you can keep, looks like this.
The reason takes deliberate effort with AI has a name worth keeping. The boundary between tasks AI handles well and tasks it fails is not a smooth line you can predict from difficulty. It is jagged: irregular, specific to the task, and invisible until you test it. Two requests that look equally hard to you can land on opposite sides of it, and the boundary moves every time the model updates.
The practical rule that falls out of a is a pacing rule. Scale how much you delegate only as fast as you scale how much you check. Handing the system more of a task is safe only to the degree the checking around it keeps up, because the place a model fails can be the very place that looks safe from the outside. The next sections build the checking that lets delegation grow without outrunning your ability to catch a confident mistake.
Three levels of checking build on each other
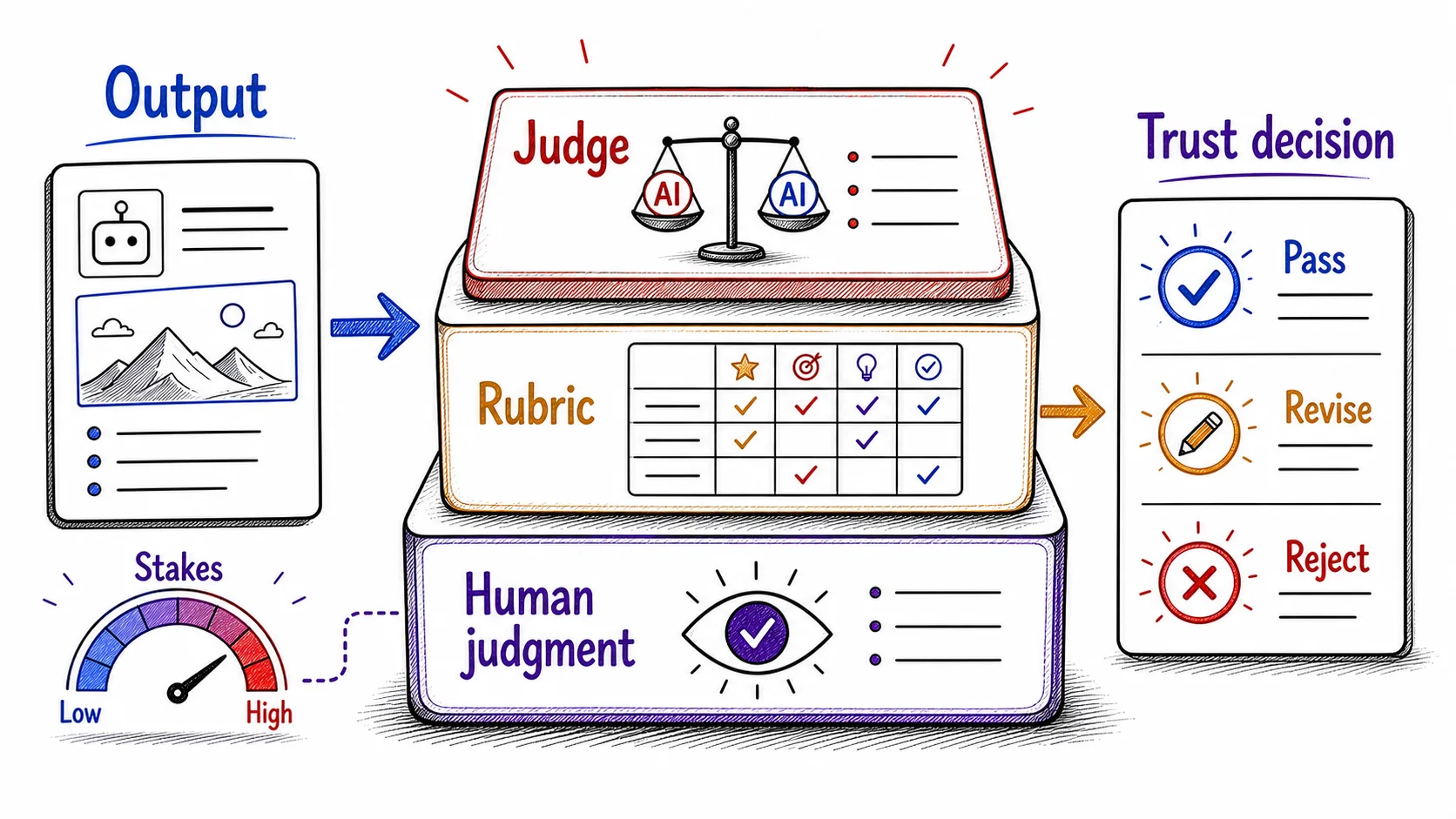
The way to make checking keep pace with delegation is to make your judgment explicit enough to apply the same way twice. The three levels are one judgment captured at three depths: your own read, a written rubric, and a judge prompt. Each level takes the judgment from the level before it and makes it portable, so the same standard reaches more output without you rereading every piece by hand. They build on each other in order, and you only climb to the next level when the task earns it.
Start every evaluation with your own read, and let it sharpen
The first level is your own taste, expertise, and standards. You read the output and ask the plain questions: does this meet my bar, is it specific enough, is it true, would I put my name on it. Everything above this level depends on it, because a rubric and a judge can only carry a judgment you were able to make in the first place. You stay accountable for the call, and you take the better read whether it came from you or from the judge prompt you built from your own read.
Your read gets more precise with use, and that precision is what the higher levels capture. The quality-ratchet chapter teaches you to sharpen it by naming the specific patterns of weak output you keep rejecting. As you name them, you can say which criterion an output violates and where the gap sits, instead of only feeling that something is off. That named precision is exactly what you later hand to a rubric and a judge, so the first level never stops improving even as the work moves up to the next two.
Write a rubric to make your standard explicit and portable
The second level is a rubric: a written set of criteria that says what good looks like for one specific task. A rubric turns a standard you have been carrying in your head into words, and once it is words it travels. You can paste it into a prompt, hand it to a colleague, or feed it to a judge prompt so the same criteria reach many outputs instead of living only in your attention on the one in front of you.
Here is the honest version of what a rubric buys you. A well-written rubric, applied by a judge prompt, holds your criteria more consistently than a tired person rereading the tenth draft at the end of the day, but only inside the boundaries you have written down and tested. It will not catch a failure you never named, and it will not notice a new kind of error that shows up after a model update. Consistency inside known boundaries is the thing it gives you, and it is worth a great deal, as long as you do not mistake it for coverage you have not built.
A rubric does not need to be elaborate. Three to five criteria are usually enough. Each criterion names one quality dimension, such as accuracy, specificity, tone, structure, or evidence, then describes what strong output looks like on that dimension and what weak output looks like. You do not write it from a blank page: the chapter shows how to ask AI to draft the rubric from a few good and bad examples, after which you correct it where it missed the distinction you care about.
Run a judge prompt in its own conversation to apply the rubric at scale
The third level uses one AI conversation to evaluate another's output. A judge prompt is a separate prompt whose only job is to score an output against your rubric. You give it the output, the rubric, and examples of strong and weak results, then ask it to rate each criterion and say why. Run it in its own conversation so it judges fresh, instead of defending work it just produced in the same thread. Once your standard is written into the rubric and shown through examples, the judge can apply it across many outputs while your attention shifts to the edge cases it flags, where you keep the final call.
A judge goes wrong in one quiet way: a judge that approves everything has stopped judging. If you only ever show it strong examples, it drifts into a pass-by-default pattern and waves through the next weak output just as cheerfully. The fix is to feed it the rejects: paste in outputs you turned down, each with the reason it failed. A judge that can tell you why a bad output is bad is one you can trust to flag the next one. Test it the way you tested the coworker, by handing it a result you know is wrong and watching whether it catches the error.
Match the depth of checking to what an error would cost
Checking everything is as wasteful as checking nothing. If you run all three levels on every output, the cost of evaluation swamps the work, and you stop doing it. If you wave everything through, the one confident mistake on the lands where it hurts. Calibrated trust splits the difference by cost, so the careful checking lands where a mistake would hurt the most and the cheap checking covers the rest.
The rule is plain: check hardest where being wrong is expensive, and trust more freely where the task is well-tested and a mistake is cheap to undo. A published client report earns all three levels. A few internal brainstorming notes earn a quick first read and nothing more. The depth of checking is a dial you set by stakes, not a fixed routine you run the same way on everything.
Picture the running example for this chapter to see the dial move. You are shaping software to fit how you live and work, describing what you want while the AI builds it. As of 2026 that looks like typing into a chat model; tomorrow it might be a voice you talk to, glasses that carry world knowledge, earbuds, or a brain-computer interface. The principle holds whatever the interface becomes. Suppose your setup can now do two things for you: draft a reminder to text a friend back, and move money between your accounts when a bill is due. The trap is uniform trust. If both came from the same AI in the same session and both read fluently, it is tempting to wave both through, or to get burned once and start rereading even the reminders.
Calibrated trust splits the two actions by cost. A misfired reminder is a small annoyance you can fix in seconds, so a quick read is enough. A wrong transfer moves money you may not get back, so it earns the rubric, the judge, and a final human confirm before anything executes. Same system, same session, two different amounts of checking, each set by what an error would cost. Where you want the storage and reuse mechanics for the rubrics and standards this produces, the reusable-AI-assets chapter carries them; here the point is only how deep to check.
A rough guide groups outputs into three cost tiers. High-cost outputs (published claims, client deliverables, medical or legal information, anything that moves money) earn all three levels. Middle-cost outputs (meeting summaries, status reports, routine messages) earn a rubric check without a full judge pass. Low-cost outputs (internal drafts, brainstorming, personal notes) earn a quick first read. The later chapters carry this further into choosing which model to use, stress-testing, and verifying sources; this chapter sets the frame.
Feed verdicts back into evolving the system that produced them
Evaluation is the step that turns a verdict into an upgrade. When a judge flags an output as weak, that flag is a clue, not the end of the story. The next move is diagnostic, and it does not have to fall to you alone: you can ask the AI to analyze its own output against the rubric and name which criterion it missed, then which part of the system let the miss through, the prompt, the context it had, the model you chose, or the workflow around it. That feeds back into , which evolves the part that failed into a stronger version of itself, which produces a better output, which the judge checks again. The verdict becomes a change to the system rather than a complaint about one result.
Every serious interaction produces two things: the output you asked for, and evidence about how well the system that produced it is doing on this kind of task. Evaluation is how you read that evidence. It is also how you check whether the rest of your loop still holds: whether the standard you keep rejecting against is catching the right things, whether a prompt you improved last month still produces what you want, whether a saved rubric survived the latest model update. Test whether the kept thing still holds, because a model update can quietly move the boundary under a standard you set when the old model was in place.
That is the compounding loop running with the brakes on. You experiment, look at what came back, and hold it to a standard. Where it falls short, you let an evaluation surface which part of the system produced the miss, improve the conditions that produced it, and save what worked. The culminating step is the one that climbs a level: you evolve the system, handing more of the judgment to the rubric, the judge, or the standard so the next run starts higher than this one did. The output you got is the cheap part; the judgment you wrote into the system is what carries to the next task. The output is temporary; the system you evolve compounds.
References
1 source- 1Navigating the Jagged Technological Frontier
Dell'Acqua, McFowland, Mollick, et al. · 2023 · Harvard Business School Working Paper 24-013, 2023.
Consultants at Boston Consulting Group were split into three groups: no AI, GPT-4, and GPT-4 with a short how-to overview. On a task that sat inside the frontier, the AI groups did clearly better, completing 12.2% more subtasks, working 25.1% faster, and producing results rated more than 40% higher in quality than the group without AI. On a task built to sit outside the frontier, the pattern flipped: consultants using AI were 19 percentage points more likely to reach a wrong answer than consultants working without it, because the model sounded just as confident on the task it was getting wrong.
The study compared no AI, AI, and AI with an overview. It did not test anyone working through a rubric and a judge. So read the three-level evaluation in this chapter as a discipline extrapolated from this evidence, not as a result the study proved: if uniform confidence is what hurt the outside-frontier group, then a standing way to verify proportionally, instead of trusting evenly, is the defense that fits the problem the study found.